
ThoughtWorks consultant Zhamak Dehghani defines data mesh as a “decentralized sociotechnical approach to sharing, accessing, and managing analytical data in complex and large-scale environments – within or across organizations.” This type of Data Architecture continues to generate interest among corporations, and data professionals will need to become familiar with data mesh architectures, such as those with data lakes or warehouses. To this end, Dehghani helped participants at DATAVERSITY’s Data Architecture Online (DAO) to understand data mesh principles and components more deeply.
Already, 41.5% of companies plan on investing in data mesh over 2023, and this percentage will likely grow in the next few years. Data mesh promises advantages to data-driven companies by increasing collaboration and agility among teams while scaling to products and services delivered.
Consequently, data mesh will remain attractive to enterprises or departments with embedded cross-pollinated teams and advanced technology. If a data professional has not already encountered a data mesh setup, they will likely do so when an organization’s business and technical functions are more integrated.
Before Data Mesh
Dehghani explained that traditional Data Architecture focuses on moving data to and from data lakes or warehouses to business operations, in addition to the technology to do so. This technology takes the form of data pipelines, a series of connected processes that transport data from one system to another.
To manage this centralized architecture, an organization needs many engineers working in tandem to handle a complex web of data pipelines. Additionally, engineers need to extract, transform, and load (ETL) along these connectors to make the data usable for business operations. See the figure below:
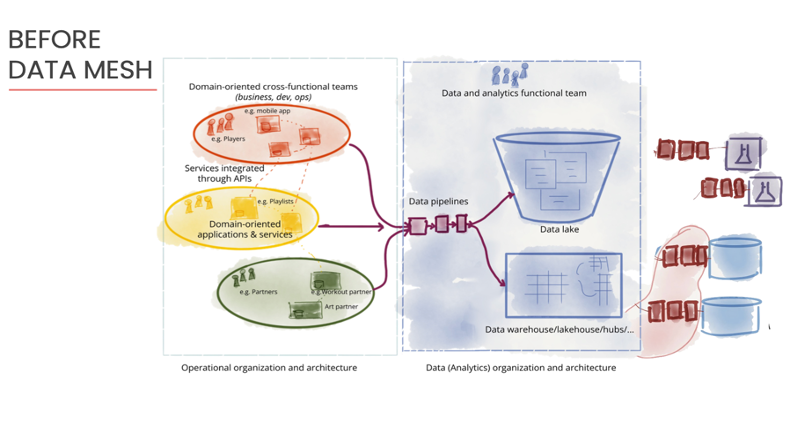
Consequently, “Data consumers experience a long lead time from data creation to its value as an asset,” said Dehghani. Furthermore, data consumers lose some context of that data upon receiving it, and lose trust in its usefulness.
After Data Mesh
According to Dehghani, the data mesh architecture capitalizes on a data-driven strategy where the company has mixed technical, business, and development teams. These cross-functional groups organize into distinct entities representing business outcomes that operate with each other.
See the diagram below of a sample company, Daff Inc., connecting artists and audiences:
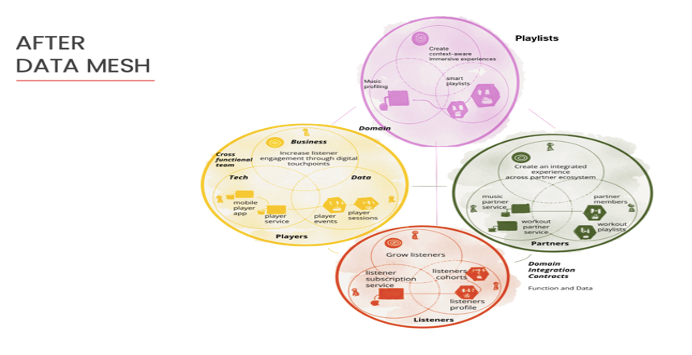
Each domain focuses on a few data solutions available to others through a self-service infrastructure. A cross-operational development DataOps team supports data movement across all the domains through automation, empowering the rest of the organization and the domain members to consume this data.
She says:
“We see a peer-to-peer approach for deep analytical sharing that scales out and back as needed. Everyone in the organization has responsibility for their data. As the organization grows with new use cases and integrates new touchpoints, a new domain gets added with a new team responsible for that data.”
What Has Changed Between Traditional and Data Mesh Architectures?
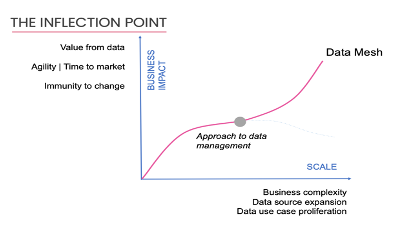
As a business becomes more collaborative, its complexity increases with a more significant number of use cases and data sources. Simultaneously, the company makes strides in adapting and getting value from its data.
Over time the organization outgrows the need for centralization and reaches an inflection point – where advancement in data’s value plateaus.
See the graph below:
Dehghani notes:
“At the inflection point, where a business turns to data mesh, it accepts the complexity and various moving parts. It acknowledges that teams have different cadences, structures, incentives, and outcomes. The Data Architecture needs to focus on managing shared data for Machine Learning ML, AI, and analytical use cases. Since decentralized and transactional data have already happened, over the last decade, with microservices and operations through APIs, data mesh naturally extends these data sharing transformations through the organization.”
Data Mesh Principles and Architecture
When an organization embraces a data mesh architecture, it shifts its data usage and outcomes from bureaucracy to business activities. According to Dehghani, four data mesh principles explain this evolution: domain-driven data ownership, data as a product, self-service infrastructure, and federated computational governance.
Each one has a dependency on the other, as the figure below shows:
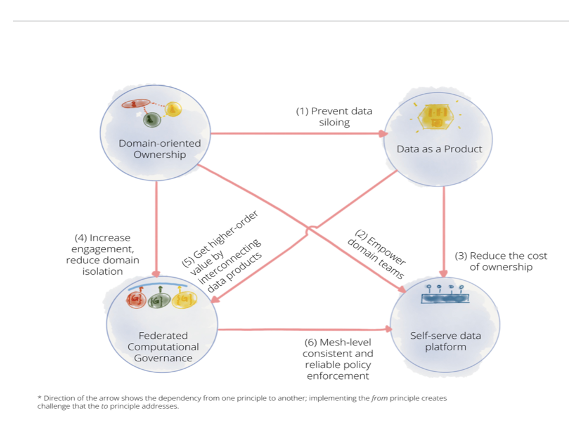
Dehghani expanded on each concept and showed their interdependence as she proceeded with her talk.
Domain-Driven Data Ownership
Think of domain-driven data ownership as a continuation of giving the business control of its data. Dehghani said,
“Domain-driven ownership results in discovering the existing business areas and teams. You ask how our organization is structured and how we can map data ownership to that. Then you find out how to connect analytical data to the domains best positioned to provide it and the APIs required. Finally, domains define service level guarantees for the APIs consumers, like data scientists and analysts, need.”
Dehghani explained that a domain needs to externalize its data with the other domains through a shared interface to use organizational data. Each domain becomes a data product owner measuring its KPIs, feedback, and goals throughout development.
Domains receive feedback from the other teams that use their products, increasing engagement, rewarding data sharing, and preventing data silos. In addition, organizations reward these domains based on their product success, creating a positive feedback loop where domains want to enable self-service, empowering other domains to provide good data services.
Data as a Product
Dehghani explained data as a product as an autonomous service for various users, accessed through preferred tools. As such, data as a product focuses on the semantics of the data rather than the syntax.
As an interoperable entity, the data product organizes around a domain and has metadata provided with the data to be trustworthy. “By keeping the same semantic data in different modes to access, a variety of data users can use data with the tools they want,” stated Dehghani.
Contrast that reality to a centralized architecture where data moves from one technology stack to another through a pipeline. In that case, using an application requires matching the syntax. So, for example, if one service does parquet processing, other teams need to use parquet to access it.
The data-as-a-product principle embodies the “smallest unit of architecture that encapsulates all the structural elements needed for sharing that data,” noted Dehghani. The code comes with the data as a logical unit, a microservice, and an architecture quantum. This flexibility reduces the cost of ownership.
Federated Computational Governance
Domain-oriented ownership and data as a product lead to federated computational Data Governance, the formalized practices among domains that increase data’s value. Every domain is accountable for having a secure and reliable product.
Consequently, domains have a strong motivation to work with others to “figure out cross-functional concerns of governance around data availability, scalability, accessibility, etc., and how to enforce them,” said Dehghani.
Since data as a product reduces the domain’s cost of ownership, it becomes invested in product integration with the other groups. Upon agreeing on policies around consistency and reliability for cross-functionality and data distribution, each domain retains the power to implement them.
Each team’s accountability to its products and other domains motivates it to enforce Data Governance policies to meet its service agreements to others. With this standardization, Data Governance decisions become embedded as computational policies and automated through the self-service infrastructure.
Self-Service Infrastructure as a Platform
The self-service infrastructure as a platform supports the three data mesh principles above: domain-driven data ownership, data as a product, and federated computational governance. Consider this interface an operating system where consumers can access each domain’s APIs. Its infrastructure “codifies and automates governance concerns” across all the domains.
According to Dehghani, such a system forms a multiplane data platform, a collection of related cross-functional capabilities, including data policy engines, storage, and computing. Dehghani thinks of the self-service infrastructure as a platform that enables autonomy for multiple domains and is supported by DataOps.
With such a Data Architecture, each domain’s costs for maintaining and owning data decrease because of the shared data interoperability. At the same time, the platform team enables polyglot platform support so that every domain has the power to apply its unique approach to experiment and build data services.
Conclusion: Extending a Collaborative Culture
Data mesh capitalizes on an organization’s existing collaborative culture that is data-driven and a mature digital business. That organization already has “cross-functional dev teams and DataOps practices, the heavily automated approaches to data,” said Dehghani.
However, the technical and operational complexity and bottlenecks mean that a Data Architecture needs to evolve to a data mesh once an organization hits an inflection point and data value plateaus. The four core principles of data mesh, as described above, unite data services across domains while preserving the autonomy and unique capabilities of each.
Want to learn more about DATAVERSITY’s upcoming events? Check out our current lineup of online and face-to-face conferences here.

Here is the video of the Data Architecture Online presentation:
Image used under license from Shutterstock.com