
Click to learn more about author Thomas Frisendal.
The Component Parts of Data Models
Back in March 2019 I published a post here on DATAVERSITY® titled The Atoms and Molecules of Data Models. The objective was to scope ”a universal set of constituents in data models across the board”.
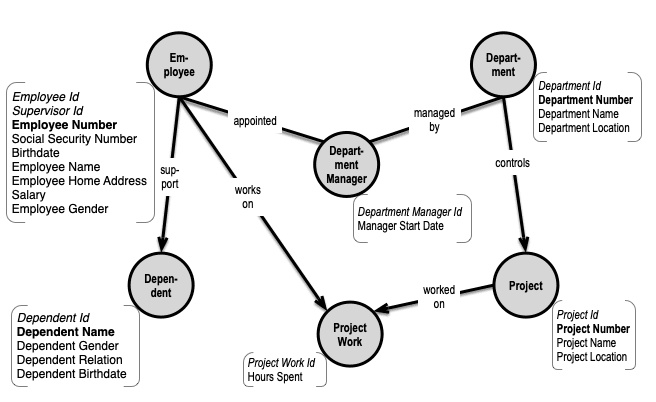
I used this classic data model, dressed up as a property graph, as an example:

The conclusion was that what you see above, consist of parts of these kinds:
- Concepts, which materialize as either
- Object types (Customer, Order etc.), or
- Properties (CustomerNumber, ProductName etc., some of which are mandatory)
- Dependencies, which structure the model as either:
- Functional dependencies (internal within the object type and determining the primary key), or
- Intra-object relationships (like “business address of” and so
forth), which have
- Cardinalities
- An associated key, which can be either a single identity or a combined set of uniqueness criteria
- a type (name, not always present)
- a direction (from/to, not always present)
- Uniqueness criteria (object type level),
- either an identifying property (key) or
- (frequently) a list of concatenated properties
- Identity (object type level),
- either a single identifying property (key) like CustomerNumber, or
- a system generated surrogate key
- Data types
I promised to come back and apply the issues of temporality to this universal model. However, it has become clear to me that that subject is too large for one little blog post.
So I divided it into 3 posts:
- Timely Concerns in Data Models (this one)
- The History of Time in Data Models (to be published)
- The Future History of Time in Data Models (to be published)
The first of the history posts will focus on 10+ of the attempts, in which we have tried (some more successful than other) to tame this multi-headed monster. The last post will try to set the scene for solving the problems in the years to come.
So, for now, let us define the problems.
Time Concerns in Data Models
Which are the concerns behind the needs for understanding and representing (date and) time in data models?
Note that time can appear to different contexts:
- An event (e.g. a sales transaction)
- A “happening” (e.g. an administrative action like registering something in the database)
- A correction of something that was previously registered, but which is found to be wrong.
“CORRECT Time”
The most immediate time is the time of when “the event actually happened”. That is in itself not a problem – it is just a timestamp. Most often captured by the system, which records the “thing”.
Recorded Time and Late Arrivals
However, systems and people are not perfect, and it happens that we do not know about happenings / changes before long time after the fact. This obviously makes reporting a bit shaky – “as good as it can be, given the circumstances”…
Think about correction of a purchase price, for instance. Could be that two weeks after some sales took place that somebody discovers that some old purchase prices had been mistakenly loaded into the system. That must be corrected, of course, otherwise the profit calculation gives wrong results. But what if part (e.g. the first week) of the corrected period has already been reported to users and maybe also clients? Not many companies like to restate results…
As-Is versus As-Of
A lot of the data content temporality can be represented reasonably well using two time-lines:
- “As-is”, which connects the content to the time to the time(-period) where the value was correct (seen from a business perspective)
- “As-of”, which connects the content to the time, when a value was recorded in the database.
One timeline keeps track of the business side of the house – what is the trusted value, when? And the other timeline keeps track of when the database was updated. So, whenever something must change, both timelines are maintained, having a new entry added, each. This is normally referred to as ”bitemporal” modeling.
It works like this:
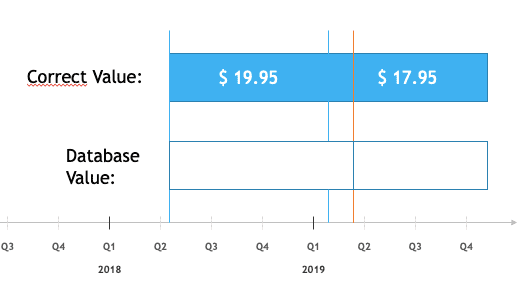
The value of $ 19.95 was good for business from early Q2, 2018, until around Feb., 2019. But the problem was that the correct, new value ($ 17.95) was not entered (for some reason) before around Mar. 1st, 2019. People during reporting in Feb. 2018 incorrectly used $19.95 (without knowing it was wrong). If you need to (e.g. because of regulatory compliance) have to explain why the reporting was wrong, you definitely need the timeline for the database updates.
The Scope of the Time (Periods)
The big question, however, is the scope of the timeline. In other words, what is it that the referenced time(s) cover?
So far, we have basically restricted the discussion to data content. And if we continue to do that, what can change (Create/Update/Delete)? The answer is, not surprisingly, the values of properties.
Strictly speaking, it is difficult to know with certainty that all properties of an object type can change as a “bundle”. There might be some functional dependencies among them, which dictates, which properties “go together”.
Better safe then sorry, so each property must have its own timelines. Giving you the easy way to prove what happened.
Read Timeline?
Aside: It may not be only Create/Update/Delete, which must be controlled. I know of public sectors, where read timelines are required.
Time Series
Time series are important in some industries, so it is not a bad idea to add “intelligence” about the specialties of timeseries (that they are ordered by time, basically).
Agile Schema Evolution
Intrepid time management is not for the faint-hearted, not least if you add schema changes to the tasklist.
In post-modern times agile development also encompasses data models, so the big question is, again, what can change?
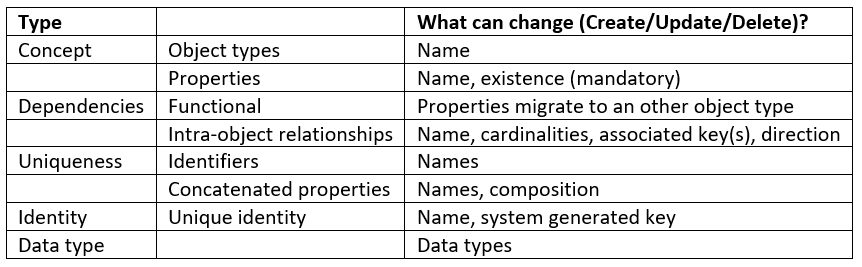
Business people are, ideally, setting the priorities, so be prepared for both structural changes and business semantics changes. On the schema level everything can change:
A Few Examples
Let us look at the example data model again:
Functional Dependencies Are Back!
If you look at the properties of Employee you will, being a data modeler, immediately see that there are a couple of dependencies playing tricks with us. All properties, except Supervisor Id and Employee Home Address, are functionally dependent on the uniqueness of Employee Number (and the identifier Employee Id). Supervisor Id is a key associated with a supervisor relationship, which is not shown in the diagram, and which we will not worry about, here and now.
Employee Home Address is functionally dependent on the uniqueness of Employee, but obviously also on something else, which in today’s government IT offerings could be called “National Address Id” or maybe simply a set of geolocations. This necessitates that Employee Home Address has its own timelines.
As for the rest of the Employee properties we could chose to “bundle” them all together on a single set of timelines, when it comes to data content changes. But that would leave us with the question of “what changed”? Social Security Number, Birthdate or Salary, for example? In order to obtain close-to-perfect precision in temporality, we will have to have timelines on each and every property.
Schema Changes and Timelines?
An obvious schema change would be the normalization of Employee Home Address out into its own “Address” object type supported by a “home address at” relationship:
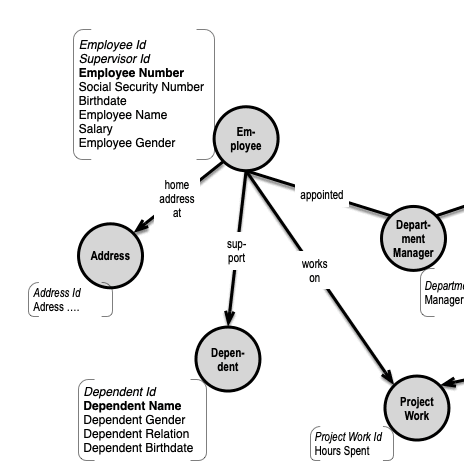
Because Employees move to another address, the relationship (or its associated key property in Employee) needs to have timelines of its own. The timelines should – ideally – support the fact that at a given date, references to “Employee Home Address” should – until further notice – follow the path (Employee)-[home address at]->(Address) – using simplified property graph notation – and the relationship is managed by timelines of its own.
Structural changes such as the above should all be supported by similar timelines(?) – (There are about 15-20 different kinds of basic changes to data models).
Is “Schema Last” Easier?
Looking at this level of complexity, it is apparent that self-documenting data models (or the “schema last” approaches of some NoSQL databases such as graph) have their attractions.
However, “schema first” is a given requirement in a number of industries (finance and government at least).
Some of this schema detection is going on today – often called “data discovery” – in tools like data catalogs and master data management etc. Solutions are indeed possible, but there is a long way to go to get to complete temporal governance.
Both temporal content handling and schema evolution are big mouthfuls that raise complexity some orders of magnitude.
And, hey, we are not done yet, there are more concerns to worry about.
Models in Times of Uncertainty
Barry Devlin, the father of the data warehouse recently posted an interesting article on Upside:
Models in Times of Uncertainty. It gives a good overview of some recent research by Lars Rönnbäck (Modeling Conflicting, Unreliable, and Varying Information) and also some comments on a book by Tim Johnston from 2014: Bitemporal Data.
The essence of Barry’s article is: ”Data models seem to represent the real world, but a model can be misleading if the relationship between truth and information is not understood.”
I strongly recommend to you that you get an overview of this area, which Lars Rönnbäck (co-developer of Anchor modeling) calls ”transitional modeling”. A subject by itself, but start with Barry’s article.
Conclusion
Temporal Data Modeling is more than simply sprinkling good amounts of time fields all over your data model. Maintaining context over time is a serious challenge.
In my two next blogposts, I will try to:
- Give an overview of the (many) different approaches, we have tried within Temporal Data Management, and
- Give some guidelines for how to proceed.
Barry Devlin also recently published an article called Combining SQL and NoSQL to Support Information Context. In it he carries ”transitional modeling” forward into an ”adaptive information context management system (ICMS)”. I, too, will try to go into solution mode – in my last blogpost on temporality.
And now for the philosophical corner:
Are we dealing with an engineering problem? We certainly tried several such approaches.
Or is this more like an “evolutionary” process? Modern linguistics are focused on context, too (look up lexical priming for example). And some psychologists are developing a “relational frame theory”, which attempts to structure the way we perceive structure and context. Are our modeling efforts really evolved traits, some of which result in real advantages?
Stay tuned – in due time!