
Click to learn more about author Dipti Borkar.
As businesses are increasingly becoming more data-driven and need to make faster, more informed decisions, the traditional data warehousing approach for accessing and analyzing data is becoming more impractical, time-consuming and likely to increase cost, effort, and vendor lock-in. It assumes data needs to be ingested and integrated into one database to provide the critical business insights for decision-making. Yet these data warehousing systems are closed source, with data stored in proprietary formats, and tend to be very expensive.
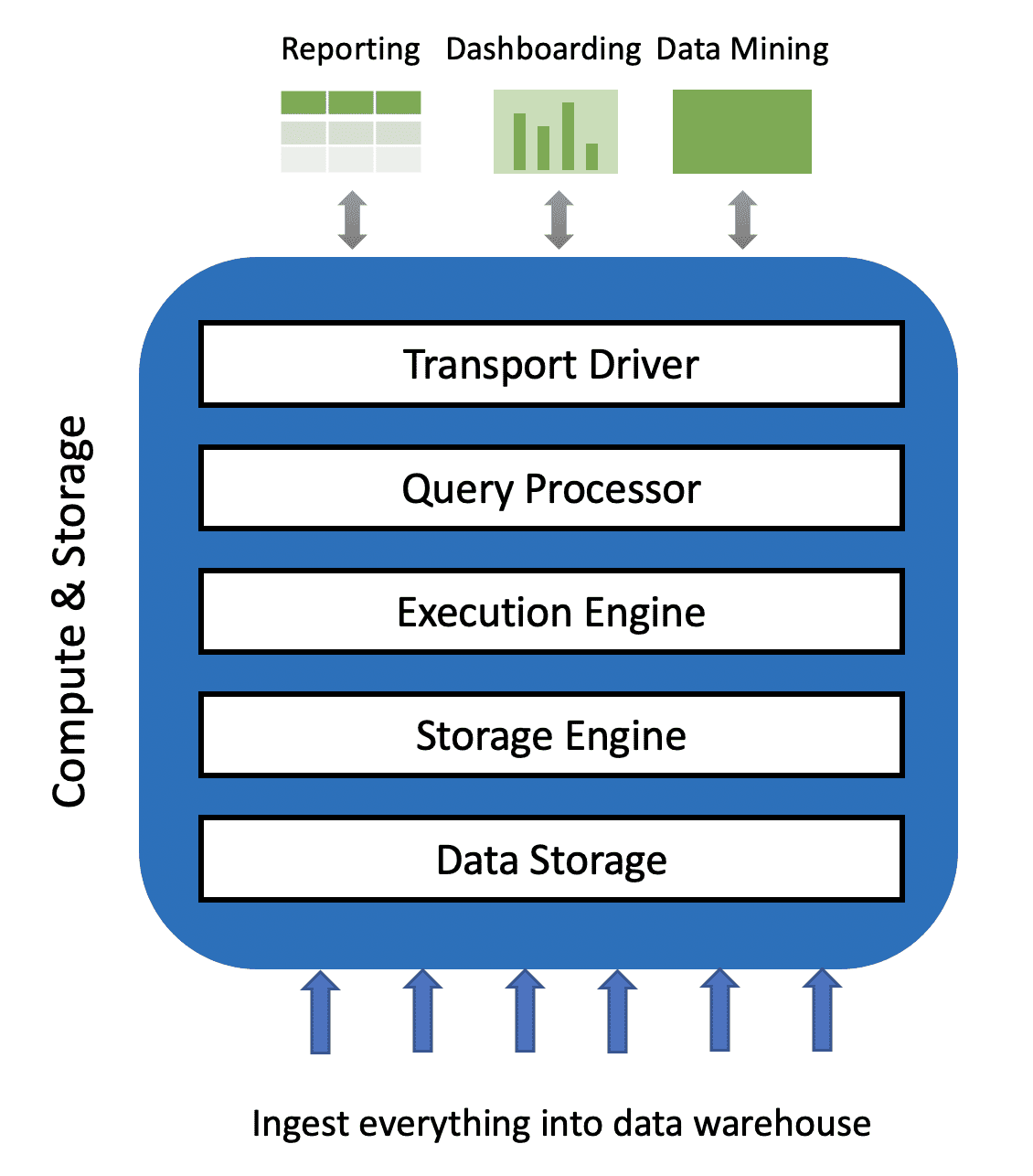
A typical organization today has data in multiple systems and most of that data is now up in the cloud, or will be soon. The data is usually a mix of structured and unstructured, static and streaming and in many different formats. Data is dispersed across data warehouses, open source databases, proprietary databases, data lakes, cloud warehouses, document stores and object storage. Doing analytics on this varied and increasing amount of data has become a higher priority in order to do business, and consolidating all of it in a monolithic system is no longer the preferred approach.
An alternative approach that is now widely deployed by the most innovative, data-driven technology companies – Facebook, Twitter, Uber, Netflix and others – consists of a loosely coupled disaggregated stack that enables querying across many databases and data lakes, without having to move any of the data. Presto is used to query data directly on a data lake without the need for transformation; your data can be queried in place. You can query any type of data in your data lake, including both structured and unstructured data.

Image Credit: Ahana
This new modern open analytics architecture is built on open source PrestoDB, which is a federated, extensible distributed query engine, created and open sourced by Facebook. It supports pluggable connectors to access data from external data sources and write data to those external data sources — no matter where they reside. These connectors are for databases, object stores, data lakes, streaming data, almost any data system Using Presto as the query engine in a disaggregated stack has become the preferred approach for these advanced technology companies – who have plenty of money to buy whatever system they want – because it not only addresses the realities of today’s data, but it also is open.
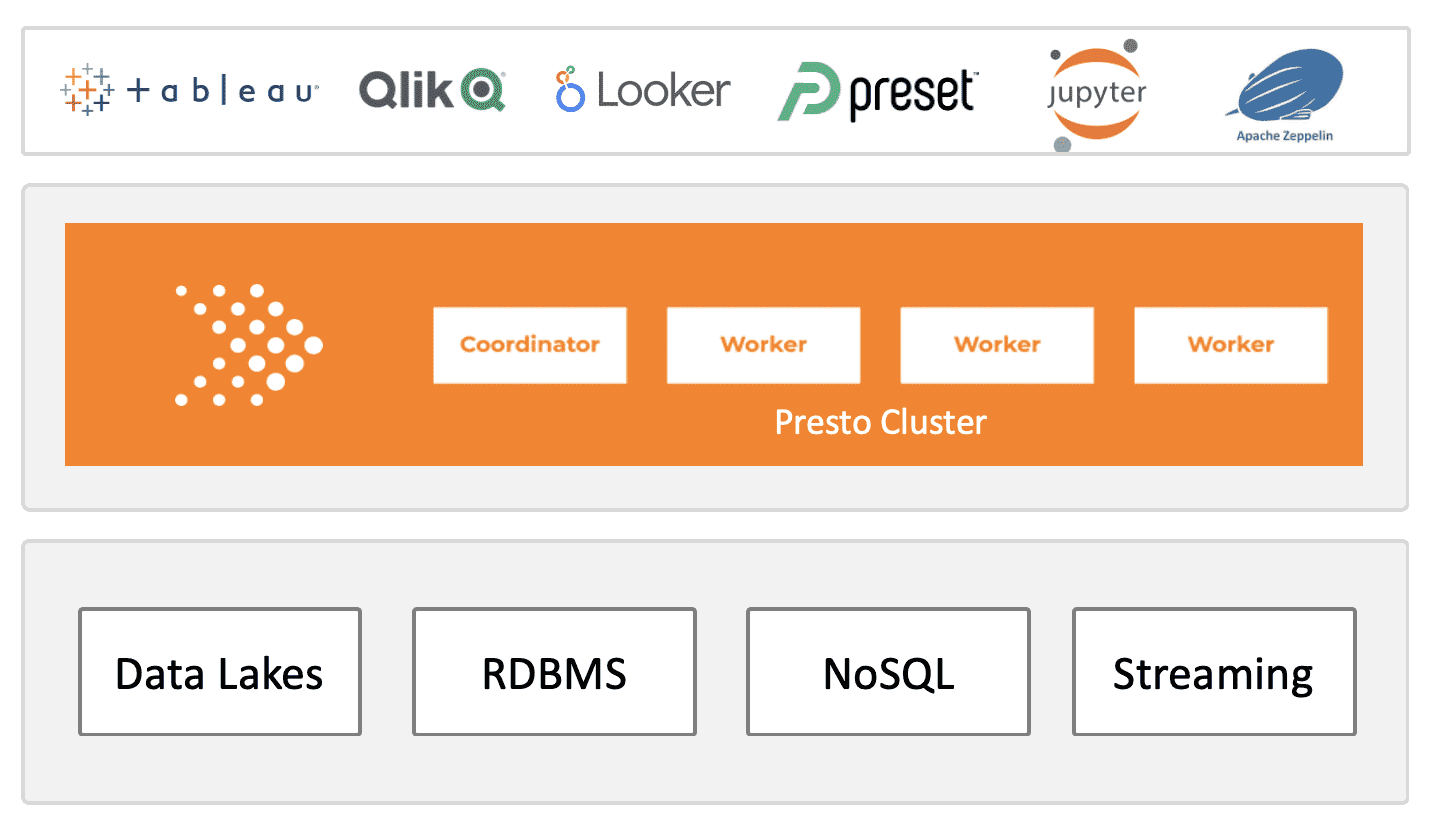
Image Credit: Ahana
Open Analytics is open source, open formats, open interfaces and open cloud.
Open Source
PrestoDB is governed by the Presto Foundation under the auspices of The Linux Foundation, and is completely open source under the Apache 2.0 license. It is the main Presto open source project. It was and continues to be developed on their public Github account, and even Facebook contributes their new mainstream features. This means Facebook runs the same version of code that you can download and use yourself for free. Facebook and many other companies are constantly testing and improving Presto, using the collective power of a community working together to deliver quick development and troubleshooting. You benefit from these innovations–not just from one vendor, but from the entire community.
Open Formats
PrestoDB doesn’t use any proprietary formats. In fact, it supports most of the common formats. With the Hive connector, Presto is able to read data from the same schemas and tables using the same data formats — Apache ORC, Avro, Apache Parquet, JSON, and more. In fact, the Hive connector is referring to the Hive metastore. The Hive connector enables Presto to query any data lake via a metadata catalog whether that is a Hive metastore or another catalog like Amazon Glue. It allows you to query data using the same metadata you would use to interact with HDFS or Amazon S3. The metadata catalog integration is a very important aspect of a disaggregated computational engine because this is what maps files stored in data lakes into databases, tables and columns and allows for SQL to be applied to query files.
Open Interfaces
By adhering to the ANSI SQL standard, PrestoDB allows for seamless integration with existing SQL systems. SQL analytics is key as SQL has become the lingua franca of data systems and is still growing in popularity. SQL is the most mainstream way to work with any database. It is easy to learn and provides a broad interoperability for the majority of databases. Additionally, standard JDBC / ODBC drivers can be used to connect to practically any reporting / dashboarding / notebook tool. And because it is open source, language clauses continue to be added in and expanded on.
Open Cloud
PrestoDB is cloud agnostic and it runs as a query engine without storage, natively aligns with containers, and can be run on any cloud. You can run Presto via Amazon Elastic MapReduce (EMR) and Google Dataproc. Amazon Athena, a serverless, interactive query service to query data and analyze big data in Amazon S3 using standard SQL, is built on Presto. Other vendors offer Presto as a managed service, such as Ahana, that make it easier to set up and operate multiple Presto clusters for different use cases.
We’ve heard that companies prefer this open analytics approach compared to the proprietary formats and technology lock-in that come with the traditional data warehousing approach. What do you think? What are the benefits you see for your organization? Any challenges to implementing an open analytics approach?