
Click to learn more about author Surya Nekkanti.
In this article, I will explain what is required and how to deploy database applications using Kubernetes. In the early days of the internet, if you wanted to launch an application, you had to buy or rent hardware, get the software from the vendor through a floppy drive or CD/DVD, get it installed, and configure the servers. It took a lot of time to get ready, to develop the code, and deploy. In 2001, VMware came out with virtualization – software that allowed users to run multiple applications on the same hardware. This meant you could split up a single box into multiple virtual boxes, each running its own environment and applications.
Fast-forward: Amazon has revolutionized the tech industry with the concept of infrastructure as a service (IaaS) with Elastic Compute Cloud (EC2), which is an eye opener for a lot of IT companies. You don’t have to buy hardware and configure the operating system.
Stateless vs. Stateful
Before developing a new application, it is very important to consider the underlying architecture. In the context of Kubernetes or in any other architecture, a stateless application is one that depends on no dependent storage. What that means is, in the context of a Kubernetes cluster, application state doesn’t store on the cluster; instead, application data stays with the client. If you take into consideration a stateful application (e.g., Oracle EBS) with one application server and one database server, when a user logs in to the application, first it authenticates against the credentials provided. Once it authenticates through the database, then it authorizes, pulling all responsibilities that the user has. Before the user log ins to the application, the state is false. After successful login, the state becomes true. When the user clicks on any responsibility or html page, it doesn’t have to authenticate again, as the state is already true.
The advantage of the stateful application: When the first call happens to the database, it stores the state of login. The second time the user clicks on any responsibility, it doesn’t have to make another call to the database, as the state (some kind of flag) is already true.

In the case of stateless application, if the user log ins to the application through a load balancer, and the load balancer pickups a server on the left side, the user can continue with other requests, as his session variable is already set to true. If the load balancer decides to make a call to the server on the right, his request will fail because he has not logged into the server. Stateful applications are not very scalable; however, stateless applications are scalable because you don’t have to store the state.
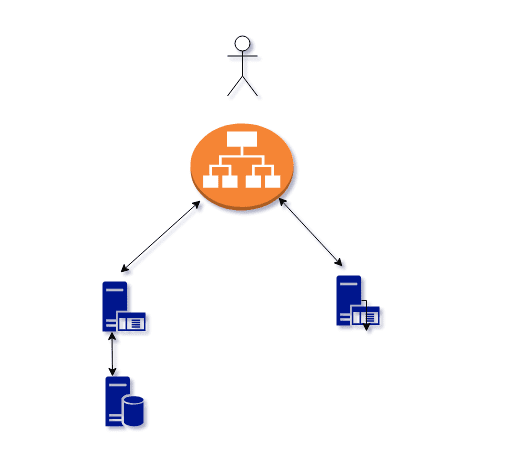
What Is Important for StatefulSet?
In general, container storage via a container’s file system is ephemeral and can disappear upon container deletion and creation. The lifetime of this ephemeral storage does not extend beyond the life of the individual pod, and this ephemeral storage cannot be shared across pods. One of the prerequisites in stateful applications is persistent storage. To provide a durable location to store data and prevent it from being lost, you can create and use persistent volumes to store data outside of containers.
Which Storage Option Should I Choose?
There are 30-plus cloud native storage vendors, including AWS, Microsoft Azure, Google, and Pure. Instead of choosing the vendor, it is better to lay out the best framework rather than giving one perfect storage solution for everything.
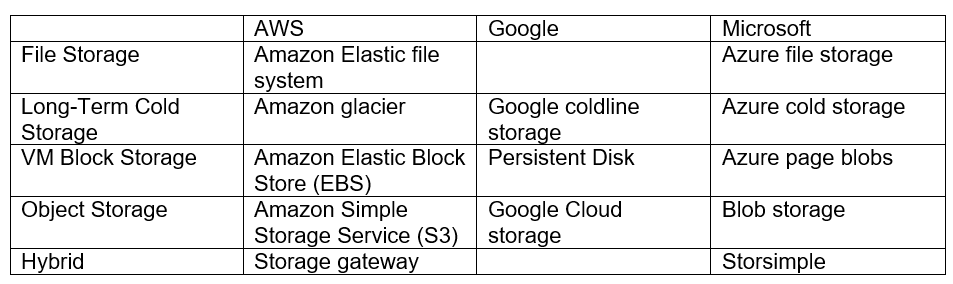
These are the basic principles cloud native storage should have:
- horizontally scalable
- Independent from the underlying platform
- No single point of failure
- Automatically recoverable on its own
- Minimal operational overhead
A storage administrator creates a persistent volume from a pool of storage volumes backed by iSCSI, NFS, GCE, etc. These storage volumes are an abstract of physical storage. A developer needs some storage; he defines and applies a persistent volume claim to your cluster, which in turn creates a persistent volume that’s bound to the claim. A claim is a block storage volume in the underlying IaaS provider that’s durable and offers persistent storage, enabling your data to remain intact, regardless of whether the containers that the storage is connected to are terminated.
Deploying Database Applications
Two things are required for database application deployment:
- Working environment of Kubernetes
- Understanding of Docker images
You can provision the Kubernetes cluster on any public cloud provider like AWS, Azure, or Google cloud. Refer to Kubernetes cluster installation and configuration steps.
To deploy databases on Kubernetes we need to follow the below steps:
- Database Docker image
- Persistent storage volume
- Database deployment
- Database service
For Oracle databases to deploy in a Kubernetes cluster, first register at https://container.registry.oracle.com and accept the licensing agreement before using this software.




Conclusion
In my opinion, deploying big database applications in Kubernetes is not a good idea, but small repository database applications, catalogs, and lookup value databases can be ideal candidates in Kubernetes.