
Click here to learn more about Dr. Chintan Shah.
Stories have been a proven medium for influencing, explaining, and teaching for ages. Stories provoke thought and bring out insights that are hard to decipher and understand otherwise. The art of storytelling is often overlooked in data-driven operations, and businesses fail to understand that the best stories, if not presented well, can end up being useless. These benefits of storytelling can be combined with the factuality of data collected by enterprises to drive informed decisions.
Organizations generate huge volumes of data, which is stored in structured as well as unstructured formats. While most organizations use business intelligence and analytics tools to analyze this data and derive insights and visualizations, they fail to analyze unstructured data contained in formats like images, PDFs, docs, etc. These unstructured formats have huge potential for interpretation and analysis. For example, a complex stock price graph image can be converted into a data story to answer questions such as “What is this month’s stock price trend?” and “What decisions can we make out of the graph?” This requires translating unstructured data into readable text.
Generating stories and captions out of images involves understanding the image and translating the understanding into natural language. While it is simple for humans to do it, machines find it difficult to understand the image and convert it into proper, accurate, and meaningful sentences or descriptions. Moreover, the image captioning model should be capable of getting the semantic information from the image, so that the story generation model can generate a good summary of the image.
Thanks to breakthroughs in computer vision, natural language processing, and deep learning methods, it is now possible to automatically generate captions from images. This article will take you through how deep neural networks automatically generate textual descriptions for images and the role of natural language generation in enabling it.
Auto-Generating Captions from Images
Image captioning is a process of explaining images in the form of words using natural language processing and computer vision. In recent years, generating captions for images with the help of the latest AI algorithms has gained a lot of attention from researchers. Attention mechanism – one of the approaches in deep learning – has received tremendous success for text and image. In the earlier versions, the caption predictor looked at the image in the encoding stage and used Recurrent Neural Networks (RNN) with attention mechanisms in the decoding process to generate the caption for the image.
The transformer architecture can be trained end-to-end without auxiliary models explicitly detecting the various regions of the image. In the recent developments in the image captioning model, a transformer-based architecture has been adopted, which can relate to regions in the image using dot-product attention to produce the most suitable caption for the image. The transformer architecture was introduced to solve machine-level translation problems. Since images can be two- or three-dimensional, image transformers are used to provide captions to images, wherein each transformer layer implements multiple sub-transformers, which find the spatial relationship for image regions, while the decoders decode diverse information from the image regions.
Once the caption is generated from the image, the GPT-2 (short for Generative Pre-Training) uses it to predict the next word and generate the story. To generate more effective stories, the GPT-2 needs to be fine-tuned with stories from various corpus.
The Framework

Image Transformer
An image transformer has a stack of multi-head dot product attention, which is based on a refining layer.
In each layer, for a given input, A∈RN×D, consisting of N entries of D dimension. In contrast to natural language processing, where a word is considered as an embedded feature, in image captioning, the input entry can be featured by describing a region in an image. The primary job of a transformer is to refine entries with the help of multi-head dot production. Each layer transformer has to transform input into Query (Q), Key (K), and Value (V), with the help of linear transformation. In the next step, the scaled dot-product attention is defined by:
Attention (Q,K,V) = Softmax (QKT / √Dk)V
Moreover, as a behavior of the transformer, the next layer will take the output of the previous layer of the transformer as an input.
Story Generation with GPT-2
To generate a story based on the caption given by the caption engine, we use the story generation engine. The caption is fed as an input into the story generation engine, which generates a meaningful story for the image as output.
The architecture of GPT (Generative Pre-trained Transformer) is very similar to decoder-only transformers. However, GPT-2 is a large transformer-based language model, which trains on a large dataset. GPT-2 has language generation capabilities wherein it can generate text samples and small stories on the basis of the input.
GPT-2 can perform well with other language models without training on specific domain inputs. It is trained on different corpus to predict the next word. With over 1.5 billion parameters, the only limitation is that it is currently in beta as OpenAI.
Training Data
To train the language model from scratch, a lot of data is required. Fine-tuning the pre-trained model will make it capable of generating decent results on the task. For this, we need to collect the data from various sources (such as Reddit, U.S. financial news articles, etc.) and split them into train and test sets.
One of the simple approaches to run GPT-2 is to run it without any specific goals, or in other words, generating unconditional samples from it. In another approach, we can provide a certain topic to generate interactive conditional samples.
If we want to generate an article or chapter, we can push all examples into one document and train it. But in the case of generating a caption for an image, it is required to generate a few sentences with specific inputs and patterns. Therefore, we need to add special tokens at the starting <title> and ending <|end of text|> of the example.
For example,
<|title|>The company’s sale has increased in the last quarter <|end of text|>
Fine-Tune
To train the model from scratch is very time- and resource-consuming. And, collecting data is another challenge. Therefore, the best practice is to fine-tune the model with domain-specific data to bring the best results based on the caption, which is generated from the previous step.
The large-sized GPT-2 model needs to be fine-tuned using the most popular transformer model. At the end of the model training, we must evaluate it using a perplexity score. The trained model of domain-specific data can produce coherent stories.
Enhancement Using GPT-3
GPT-3 is one of the most powerful models to date for text generation. The model has 175 billion parameters and can generate longer stories on the basis of inputs. However, it is not trained on domain knowledge, though the model can generate stories for certain domain-specific tasks. For GPT-3, there are no direct download links available yet. The only available source is OpenAI, which provides a restricted cloud-based API.
Fine-tuning GPT-3 is one of the greatest challenges because it requires access through API. Moreover, the weights are available only to a specific group of users. Due to such restrictions, it is currently not feasible for everyone to fine-tune GPT-3 for specific domain data.
Therefore, GPT-2 is used to fine-tune domain-specific data and generate more comprehensive stories based on the predicted captions.
Key Takeaways
- Pass image into image transformer
- Get the predicted caption and pass it into the fine-tuned GPT-2 language model
- The fine-tuned GPT-2 generates a short story based on the caption
Illustrated Example
Here’s an image of a stock price trend chart for a leading firm. On passing this image into the captioner model, it processes it and generates the below caption along with a short story:
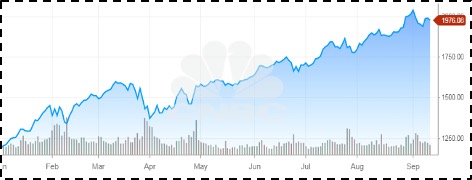
Predicted caption: Stock price increased in the past year
Predicted story: The stock price increased in the last year from 1250 in January to 1976 by the end of September. The trend shows a fluctuation in the price and volume throughout the year. The share price was at an all-time low in January and hit the highest at the beginning of September.
References
- He, S., Liao, W., Tavakoli, H.R., Yang, M., Rosenhahn, B. and Pugeault, N., 2020. Image captioning through image transformer. In Proceedings of the Asian Conference on Computer Vision.
- OpenAI. 2021. Better Language Models And Their Implications. [online] Available at: <https://openai.com/blog/better-language-models/> [Accessed 25 February 2021].
- Karpathy.github.io. 2021. The Unreasonable Effectiveness Of Recurrent Neural Networks. [online] Available at: <http://karpathy.github.io/2015/05/21/rnn-effectiveness/> [Accessed 21 February 2021].
- Medium. 2021. AI Writing Stories Based On Pictures. [online] Available at: <https://izzygrandic.medium.com/ai-writing-stories-based-on-pictures-52b3ddbcd7d> [Accessed 01 March 2021].
- Ray, T., 2021. What is GPT-3? Everything your business needs to know about OpenAI’s breakthrough AI language program | ZDNet. [online] ZDNet. Available at: <https://www.zdnet.com/article/what-is-gpt-3-everything-business-needs-to-know-about-openais-breakthrough-ai-language-program/> [Accessed 8 March 2021].
- OpenAI. 2021. OpenAI API. [online] Available at: <https://openai.com/blog/openai-api/> [Accessed 12 March 2021].