
Click to learn more about author Mark Marinelli.
Most of you have heard the term DevOps, which refers to a popular practice where development and operations teams work together to deliver applications faster. It’s time we bring that same notion to the data world with DataOps so that we can achieve agile data mastering:
- Agile Data Mastering (n): A modern Data Management technique to rapidly and repeatedly unlock value from a wide variety of data sources by combining highly automated, scalable, cross-domain data unification technologies with a rapid, iterative, collaborative process.
In order to put a DataOps framework into place, you need to structure your organization around three key components: technology, organization, and process. Let’s explore each component in detail to understand how to set your business up for long-term data mastering success.
1. Technology
An organization’s technology is comprised of two main elements: architecture and infrastructure.
Architecture: Technology architecture is the set of tools that comprise your data supply chain. This is how you oversee and execute your entire data mastering process. To follow the DataOps framework, your technology architecture must be comprised of the following principles:
- Cloud First: Companies are opting to start new data mastering projects natively on the cloud which significantly reduces project times and are designed to easily scale out as needed.
- Highly Automated: Automating your data infrastructure is essential to keep up with the rapidly expanding scope and volatility of data sources, as the manual or rules-based approaches to data modeling and management are impossible to build and maintain economically.
- Open/Best-of-Breed: Using a combination of platforms allows you to have the best-of-breed for each component of your infrastructure. Never be married to one piece of software and always keep up to speed with new technology and platform options. It’s a bit more work in the beginning than choosing an end-to-end solution from a single vendor, but the ability to mix and match–and most importantly replace–components as your data landscape evolves is a huge dividend.
- Loosely Coupled (Restful Interfaces Table(s) In/Table(s) Out): Tools should be designed to exchange data in tabular format over RESTful interfaces. This avoids dependency upon proprietary data formats, simplifies the development of data applications, and aligns with how consumers intuitively interact with data.
- Tracking Data Lineage/Provenance: Having a clear lineage to the origin of your data makes it far easier to debug issues within data pipelines and to explain to internal and external audiences where the answers to their analytics questions actually came from.
- Bi-Directional Feedback: A major problem many organizations face is having the right infrastructure in place to collect valuable feedback from data consumers they can then prioritize and address. Systematic collection and remediation of data issues – essentially a Jira for data – should replace the emails and hallway conversations that never make their way back to corrections in the sources.
- Process Data in Both Batch and Streaming Modes: The ability to simultaneously process data from source to consumption in both batch and streaming modes is essential to long-term data ecosystem success as data arrive with varying frequencies and applications have different requirements for data refreshes.
Looking for a deeper dive into the technology architecture needed for the DataOps framework? Check out Key Principles of a DataOps Ecosystem.
Infrastructure: Technology infrastructure is all of the platforms you use to support the architecture such as Data Management, computing, storage, and infrastructure. There are myriad options for each component of the stack, including open source and proprietary technologies, and on-premise and cloud deployment modes. It’s easier (and more affordable) than ever to build a scalable platform for data mastering. Advancements in prem-to-cloud and multi-cloud offerings make it increasingly easier to move data locations on a per-application basis, accommodating a mixed set of data security requirements and enabling shifts in data gravity.
2. Organization
If you want to run a DataOps team successfully, the way you structure and run your entire organization needs to change. For starters, you need to upskill your team and clearly define data roles. I get specific about what this entails here, but on a high level just know that every member of your organization must have clearly defined roles and responsibilities as depicted in the below org chart:
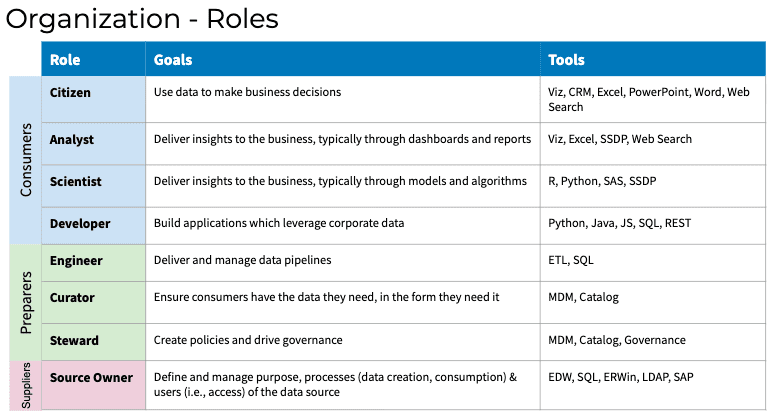
Depending upon your existing organization, filling these roles will require a mix of upskilling internal staff and sourcing new skills externally. Some of these roles won’t be full-time positions initially, but as your organization scales, having dedicated specialists for tasks like data curation and stewardship will enhance the efficiency and effectiveness of your organization.
The second component of a DataOps organization is its structure. There are two models to consider; the advisory model and the shared services model.
- Advisory Model: the team bootstraps projects with best-of-breed tools and approach, but does not complete them. The advantage of this structure is in the concentration of technical expertise to evaluate new technologies, but advisers don’t actually implement these technologies as production systems, so they do not benefit from the direct experience of applying tools to solve different problems.
- Shared Services Model: the team provides full-service development of data applications, in collaboration with business. This team will accrue more knowledge across projects, and is attractive to line-of-business teams that require a comprehensive solution. However, these resources will be in high demand, which can present challenges when trying to prioritize projects across contending departments.
Since each model has its own advantages and disadvantages, it’s important to
choose wisely based off the scale of your DataOps project.
3. Process
Traditional data mastering processes begin with exhaustive requirements gathering, then proceed to heavyweight data modeling and rules development, and eventually provide outputs which the end users can (hopefully) leverage. This takes months or years to complete as rules are codified, and leads to a system which is difficult to rework when end users uncover issues with the data, or when the data simply change. Even worse, the data is often outdated or untrustworthy due to limited expert involvement or limited scope of accessible data. Most of these waterfall projects either fail entirely due to lack of value generation, or significantly underperform versus expectations and budgets.
The waterfall mastering process process is labor-intensive, monolithic & IT driven:

Agile data mastering processes focus on quick starts with subsets of the data, build upon this initial foundation with incremental value delivery, incorporate iterative direct feedback from end users, and leverage technologies such as machine learning to augment or replace the complex rule sets which have historically been used to build data pipelines. These projects succeed because they deliver initial value in weeks and are more easily tuned as both source data and applications change.
The agile mastering process is automated, incremental, collaborative:

Final Thoughts: DataOps Is a State of Mind
We live and die by the agile data mastering philosophy and we’ve seen it pay off in big ways for organizations who have implemented the practice.
The most important thing to remember about creating a successful DataOps framework is to change your entire state of mind. Stop thinking in absolutes, and start thinking about how the pieces work together to create the whole. Don’t boil the ocean with endless waterfall projects. Don’t that one single platform or vendor is the source of truth. Do empower your team to think and act like a development organization.
Change your mindset and combine it with an upskill of your technology, organization, and overall process and you will successfully achieve the DataOps framework.