Click to learn more about author Thomas Frisendal.
Building Data Models from Meta Models
Recently, I worked with a government client on a Knowledge Graph kind of project. Being government, much of their data is public information. And, consequently, so are the data models. Instead of diagramming the same data all over again, I decided (lazy as I admit I can be sometimes) to try to automate the construction on the target data model.
The physical source data model was not a good candidate as a new target data model for several reasons, mostly related to the fact that the physical model was created over decades. It contains a number of compromises because of old data integrations and so forth. So we had to refactor the thing to become a new data model.
Loading and Analyzing the Source Conceptual Data Model
The as-is open data model was documented in two ways:
- A UML data model, which was published (on http://grunddata.dk/english/) as a downloadable XMI file using Danish terminology, and
- JSON structures
Being old school I chose the UML derivative. I downloaded the file and tried to load it into a graph data base (Neo4j, https://neo4j.com ). Neo4j has a monumentally large library of awesome procedures on Cypher (it is called APOC, Cypher is the SQL of Graph Database). A few of the procedures can load XML files into the database. And that is just what it did. No settings, no nothing other than a URL to the file:

The result was a XMI structure having this kind of schema:

So what we got was a graph with a linked, hierarchical structure of the information and all the terminology in a connected manner. 3 node types: The XML Document, XML Tags and XML Words.
What remained to be done, was first of all to find the “business entities”, which I prefer to call “business object types”. The way the XMI is structured makes this easy and it basically can be done like this:

(Technically this is modeled in the UML by a combination of classes with attributes and also by some user defined data types, which is why the command has two parts in the where clause).
That resulted in a graph looking like this:

The blue nodes are the business objects, which we just found and stamped as “ObjectType” in the Cypher command above. The rest of graph is basically about:
- The top of the hierarchy (the model, in the middle), and
- The leaves, springing off of the business entities are the properties of those business entities.
So far so good. What else do we need? Relationships, of course. There are relationships in the XMI structure, but they are concerned with the XMI, and not with the business. As a matter of fact, there are no business level named relationships in the UML model. So we have to name them. Finding them is rather easy:
- A bunch of “:PART_OF” relationships ties the object types to the model
- That helps us find the relationships, which are coming out of the business object types and we will have to give them good, business facing, relationship names.
Autogenerating a First Cut Logical Data Model
So now, we are ready to create a logical data model (first cut) from the conceptual structure.
I will only show you the first Cypher command in the chain of 4:

That step creates a bunch of logical level object types representing the object types of the conceptual model.
3 additional steps (Cypher commands) establish:
- The properties of the object types
- The functional dependencies between properties and their identifying object types, cf. the above)
- Lineage backwards between the logical model components and the conceptual model components.
The same 4 steps may be repeated with slight variations in order to create a physical model.
Conclusion so far:
With only 8 Cypher commands you can create a first cut logical data model from a XMI-representation of a UML Data Model.
You will need to write more Cypher commands for your refactoring of the data model:
- Naming of the relationships (but they already exist with a generic name)
- Transformations that you wish to apply (for example splitting, merging, versioning etc. etc.)
Wanting to double check, I found another open data example of an XMI-file representing a data model. It was created using some UML ORM facilities, which make the XMI slightly different:
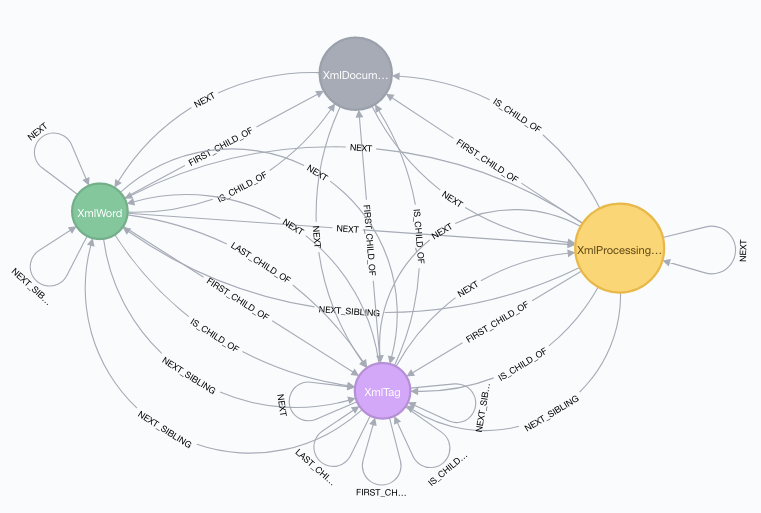
Notice that there are now an “XML Processing Instruction” node type, but we do not have any benefit of that. The use of XML Tags is a bit different (some other tags etc.), so we would have to adjust our Cypher commands to them. The set of commands is re-usable, however, within the same kind of UML context.
We have now established that it is indeed possible to use Graph Analytics to speed up the process of constructing data models (from UML models in XML).
Using Graph Technology for this kind of meta analytics is highly appropriate: Much of the work of the data modeler is about visualizing (diagramming) data structures. Having the structure already in a graph eliminates the need for drawing diagrams.
Are there other opportunities to be explored?
Autotransforming Concept Maps to Become Logical Data Models
One of my favourite tools for diagramming is the concept mapping tool CmapTools, which comes out of the Institute of Human Machine Communication, IHMC, in Florida.
In 2012 I wrote a book about using Concept Maps (CmapTools) as a conceptual modeling tool, and there are quite many modelers, in particular in the BI and Analytics space, who have adopted it.
In June of this year I did the UML XML Analytics described above, and it occurred to me that Concept Maps maybe could be split and analyzed by Graph Technology. One of the storage formats for CmapTools is XML-based.
I didn’t have time, but back then Sander Robijns (@srobijns), a fellow Data Modeler from Estrenuo in Holland, had just written a nice and very true blog post called “Concept maps and graph data modeling: techniques in the ‘data modeler toolbox’”. I commented on it on Twitter June 17th, and I challenged everybody to:
- Save a CmapTools concept map as “CXL” (XML)
- Load it into Neo4j using the APOC library
- Transform it to a graph metamodel using Cypher
- Generate Cypher “DDL”
Well, Sander was quick, and accepted the challenge right away and already on June 21st he published a solution on his blog: “Challenge accepted: turning a CmapTools concept map into a graph metamodel in Neo4j (long read)”
This is really impressive, because he actually solved the issues and he did it without much previous experience with graph technology beforehand! Well done, Sander!
Here is what he did in order to “accomplish the mission”:
(I urge you to read all the details using the link just above).
- He saved a Concept Map as a “CXL” file, which is actually XML
- He found the XML representation of the components, incl. the “linking phrases”, which become relationships in the graph model
- He loaded the graph using the APOC-library resulting in nodes for concepts, linking phrases and connections (all in one command)
- In order to arrive at a logical graph model, he had to do this:
- Create relationships between the concepts and linking-phrases
- Create relationships between the originating and target concept, bypassing the linking-phrase node in the middle
- Remove the connection nodes
- Remove the linking-phrase nodes and their relationships
- Remove the concept label and properties (except name) from the nodes
- All of this is five commands (which are reusable over and over again).
The result is a nice, first cut, logical graph data model:

(Illustration from Sander Robijns blog post of June 21st, 2018).
One peculiarity about concept maps needs to be handled: In Concept Maps both business object types and their properties are concepts, which should ideally be split into node types and properties in a logical graph data model. The rule-of-thumb for doing that is to look at the “linking phrase” (the name of the relationship). If the linking phrase contains a verb, then it is not a relationship between an object type and a property. In reality properties depend (“functionally”) on their object type by way of very passive and generic linking phrases such as “has” or “consists of” or “described by”. So, some level of automation (machine learning for the enthusiastic, maybe?) is certainly within reach.
Thanks for the good work, Sander!
The Outlook for “Metadata Science”?
Does it stop here? Not if you ask me.
I am a believer in a 3-level Data Architecture:
- Business Level (formerly known as “conceptual”)
- Solution Level (formerly known as “logical”), and
- Physical Level (whatever it takes)
The solution level is sort of the “Metadata Master Data” of the IT supported solutions. It accepts transformations from the business level and it displays transformations to the physical level.
So for top-down “Metadata Science”, we have, right here, identified:
- UML / XMI
- Concept Maps (CmapTools)
But there must be more to come on the business facing side. What about the Fact Models? What about requirements tools? Show me the metadata!
What about Natural Language Processing and Machine Learning? Yes, indeed. I have previously covered the application of such technologies to Data Modeling in a couple of blog posts here on DATAVERSITY:
- “Talk to me, Data!” – Getting Data Models Right
- Artificial Intelligence vs. Human Intelligence: Hey Robo Data Modeler!
The focus among the vendors seem to be on bottom-up (building Data Catalogs, for example), and not so much on the business level. But Metadata Automation at that level will have a significant impact, once it is ready.
There are some fast movers these days:
- Neo4j has an ETL tool, which morphs SQL databases into graph models
- Octopai has an extensive package for “automated metadata discovery & lineage for bi”
- Hackolade is busy doing visual modeling things in the NoSQL space
- And there is a whole lot more going on, not least in data catalogs
I think: This is indeed the era of the emergence of “Metadata Science”. Metadata Science does similar things for metadata as Data Science does for data. And does it add business value? You bet!