
Automated machine learning (AutoML) is no longer a new topic, but it’s still a growing trend in terms of the impact it’s having on businesses and employees. The main idea of AutoML is that it can help democratize data and data processes, providing people from any level or department of a business with the tools and platforms they need to create their own machine learning (ML) apps. These could be trainees or experts in a field who know their craft but need ready-made solutions to help them master the coding elements required to apply AI to what they’re doing.
What Is AutoML?
AutoML is a process of automating some of the most repetitive and time-consuming tasks along the machine learning (ML) journey. Normally, Data Science and ML models are seen as “blackbox” models, where it can be tricky to understand the statistics or underlying logic at work. Instead, AutoML aids non-Data Science users to use ML without comprehending the exact logic behind them.
AutoML frameworks provide transparency into various experiments and their outcomes with the aim of arriving at the best model/parameters for a given business case. Most AutoML frameworks provide no-code and low-code support to data scientists and business users, enabling them to customize various parts of the ML pipeline depending on their requirements.
AutoML vs. Machine Learning (ML)
There are multiple complex steps to build a robust ML pipeline. Broadly speaking, ML projects require training and “inferencing” (which means putting a machine learning model into production), with the training part consisting of various time-consuming steps, including:
- Data preparation
- Preprocessing
- Exploratory data analytics
- Feature engineering
- Feature selection
- Experimenting with various models
- Explainability of each model
- Selecting the best models to satisfy business use cases
Once the suitable model is selected for inferencing, further infrastructure needs to be developed depending on the technical architecture, or tech stack, being used. Selecting a suitable model will depend on the project and its vertical. Moreover, there will be various KPIs each ML model could be measured against, including accuracy, precession, recall, F1 score (for classification), and so on. Finally, there are the different error measures for regression problems.
Managing and executing all these steps is very time-consuming and requires a high level of technical experience and knowledge.
This is when AutoML comes in handy. It helps business or technical users to find actionable insights about the data, without going through all the modeling and experimentation hassle mentioned above. Therefore, AutoML can help quickly realize the value of applied ML to data. The idea is to have very little human intervention in predictive modeling and obtain quick results.

By automating various steps in training, AutoML means data scientists and domain experts can select the best model for a given use case. Most repetitive and time-consuming tasks can be automated with AutoML (see above).
Why Use AutoML?
AutoML can help a business gain initial insights into its data at a faster pace, prior to investing in predictive analytics. Today, most cloud providers – or cloud “hyperscalers” – offer AutoML as a part of their cloud offering. These allow a user to simply upload their dataset, and within a few clicks, trained models can be deployed for predictions. However, in most practical applications, the data processing and preparation for machine learning would still need to be addressed.
Let’s use an example to better understand how AutoML can help.
Use case: Understanding customer complaints about products and redirecting them to their respective teams to address them.
Current Scenario: Say you’re receiving complaints about various products that could eventually erode customer satisfaction. Currently, you have a team working part-time to look at these complaints manually and redirect them towards their respective departments. Businesses are growing alongside their product lines, so it’s getting increasingly difficult to serve customers within a reasonable timeframe. Complaints are coming in through company portals, emails, phone calls, and tweets, and not every incoming message is a complaint. But you have data consisting of the text of feedback from the respective department.
Potential solution: An automation component is developed to take on the task, speeding up the process to support the team reading the messages and redirecting them. The following images show the current scenario and the potential streamlined solution.
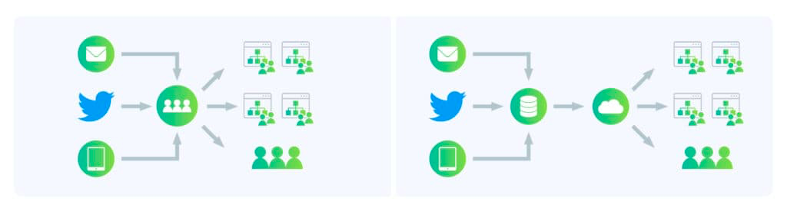
Here’s another way to look at how the automated system works:

It’s time to dig deeper, now that we understand the basics of the solution. Asking the following sorts of questions can help us find the means to achieve the desired level of automation.
- How do we get all the messages at a single place/database?
- How do we understand if a message is a complaint or not?
- How do we determine which department receives a complaint?
- How do we trust the results of this automation?
- Thinking of the future, if we scale the business to serve millions of customers, what would be the complications?
- Do we have enough data and resources to apply machine learning?
How to Start Experimenting
In almost all cases, it’s best to start small. Wherever possible, split the complex decision-making process into tiny chunks. This way, each piece of this complex puzzle can be analyzed and addressed efficiently. For example, in the above use case, one can split the whole problem into the following stages:
- Data collection strategy
- Data storage and associated technology
- How can we automate the above step?
- What is the scope of automation and is ML required?
- How can ML help us and what kind of ML problem is it?
- How do we model the data and show the value to businesses?
- Start with AutoML technology to realize if ML assists in solving the issue
- Engage with the engineering team to build end-to-end infrastructures
- Address and automate smaller chunks
Once the complex challenge is divided into smaller segments, you’ll need to automate repetitive tasks. For example, in the above use case, applying an ML classification to incoming feedback can help in tagging a particular comment as a complaint. Once a complaint has been identified, we can apply another ML classification to tag where any given text belongs.
Experiment and Experience Machine Learning
Let’s assume the chosen AutoML component has satisfactory results. In this case, we need to invest in making this process standard and scalable. If we look at the following chart, this is essentially what we have done above for applying ML.
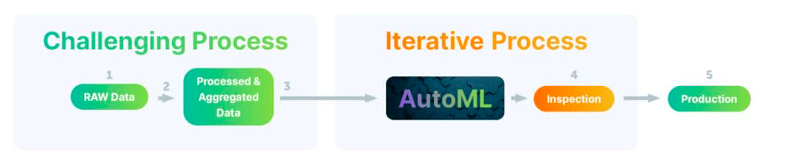
How to Apply AutoML in Practice
Finally, let’s talk about the practical complications. If data is easily accessible, AutoML can help us quickly reach a state where we can apply ML. Often, however, this is not the case.
Raw data exists in various formats – extracting such raw data and storing it in an easily accessible format and place is a crucial step. When we are looking at relatively smaller data sets, it is easy to move the data from A to B and apply ML. But, if we have data growing exponentially, also in different formats, it would be a difficult task to push this data to AutoML.
With this, we can understand that it would be easier to experiment with AutoML if/when we have easy access to the data in a convenient format. But practically, many companies struggle (for inevitable reasons) to establish central data repositories that can be used for advancing the analytics.
So, to use and get most of AutoML or any other ML technologies, it is essential to have robust, scalable, flexible, and maintainable pipelines where source data can be stored efficiently into a place where ML pipelines can work. In other words, you need easy-to-use but powerful ETL (extract, transform, and load) tools and a powerful database, where loaded data can be handed easily to AutoML.
The ideal solution would be to have AutoML components integrated into a database, such that users wouldn’t need to go through the pain of handling or building large datasets. Such solutions would be most user-friendly and effective. Bringing the power of ML close to the data gives more flexibility to data scientists, who can easily run experiments with it. If this component is AutoML, it gives additional freedom to semi-technical users to apply advanced analytics.
So, to get maximum advantage of tools such as AutoML and to use it in practical use cases, the supporting extensions for ETL/ELT and post-modeling infrastructure such as deployment and monitoring are also essential. In the coming articles, we will cover multiple end-to-end machine learning pipelines.