
Click to learn more about author Thomas Frisendal.
Common wisdom has it that we humans can only focus on three things at a time. So, I had to cut down my January 2021 list of things of importance in Data Modeling in this new, fine year (I hope)!
Looking at them from above, as we will do here, it is evident that even just three things are a handful!
The three things are contextualization, federated semantics, and accountability.
Contextualization
I am deeply concerned with perception leading to cognition and their roles in Data Modeling. Get that right, and you have successfully communicated both structure and meaning with minimal effort. We humans are very good at perceiving based on sensory inputs (visuals, mostly). So, here is a context:

Oops, a LION! Male, not really trying to hide in the grass — you got that right! But not a rich context to make decisions from. Follow your instincts (running back to the car is a fine idea).
And here is another context:

Oops, another Lion! A little more context to work with — this time, it is a female, and she probably has a full stomach. The beast (Wildebeest?) has almost been eaten. Inference: She is not hungry at this time. Take a picture and back off, nice and quiet — seems safe enough for a world-class photographer like you…
“Lion” is a category, which is something we are trained to do — putting labels on objects is useful for fast cognition. Contexts represent sets of information, and there can be considerable overlap:
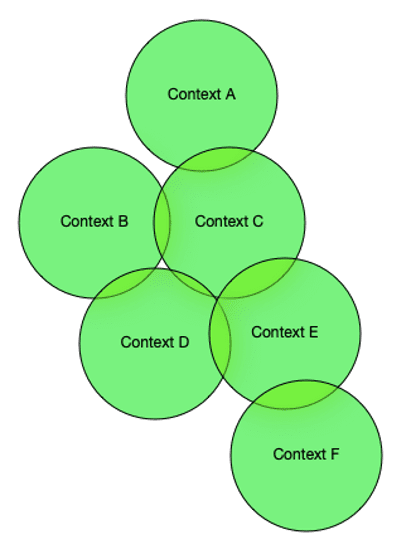
Image Source: Thomas Frisendal
So we establish huge numbers of contexts over time, and we know the intersections with some precision. But there are more relationships than the sharing of contextual elements. We recognize several variations of relationships, be they cardinalities, optionalities, inheritance, associations, and more:
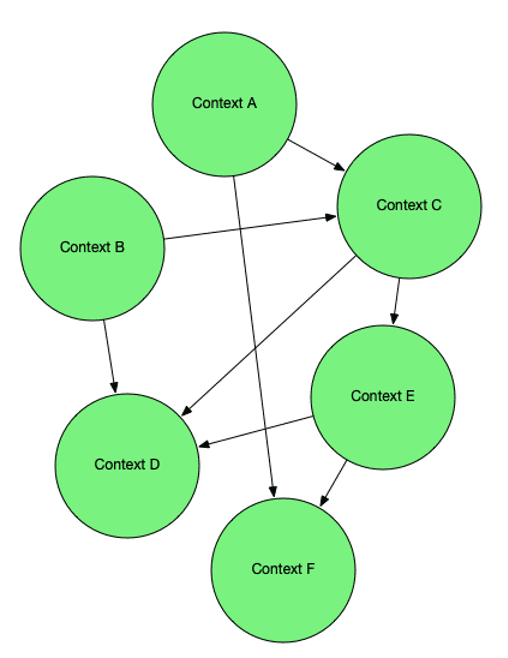
Our context repository is a graph — highly connected with a variety of cognitive semantics. These days, we (data modelers and developers) work our way through one context at a time but contextualize everything according to the bigger picture of acquired contexts and perceived relationships. We are being paid for delivering contextualization that works and has long-lasting value!
This perspective has a brand name these days: “Knowledge graphs” — and it is there for you to apply. Just do it! This recommendation will hold for 2021 and onwards.
Federated Semantics
In direct continuation of contextualization, we run into the second focus area for 2021: Use the semantics that we already know! I stated above that relationships come in types (classifications, hierarchies, multiplicity, etc.), but they also come as categories: “is-a,” “has,” “identified-by,” “ordered-by,” “located-at,” and so on and so forth.
Information professionals will know that the basic building block in semantics is:
Subject -> Predicate -> Object
These triples represent not only information but are rather a holistic view of the narratives of the business.
Subjects and objects, which express the semantics of “actors” and “things,” represent the information parts. And predicates represent the processes that the business transacts (order, register, forget) on those information parts.
That is why semantics express most of everything — even if people have a divided view of “data” versus “business processes.” Where do we keep semantics today? Data professionals build them into data models. They tend to treat relationships lightly, at least in SQL, whereas in graph models, relationships shine. Information professionals build semantics into ontologies, using RDF and OWL, having both metadata and information in one integrated (self-describing) database.
Why on earth are we not better at reusing this metadata? Well, in 2021, we will show the world that we have grown up.
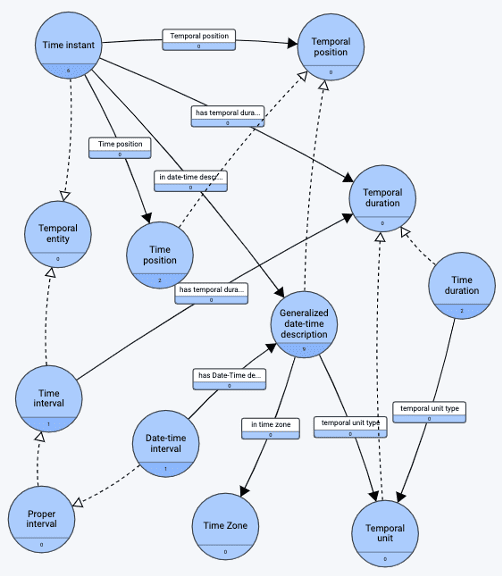
In the Webprotege community, they are busily working on a visualization tool for translating OWL ontologies into labeled property graphs (LPG, Neo4j style):

Over at data.world, their very nice-looking OWL/RDF editor, Grafo, is also becoming “LPG-fluent.” First, a snippet of an OWL-ontology:
And then a snippet of an LPG model:
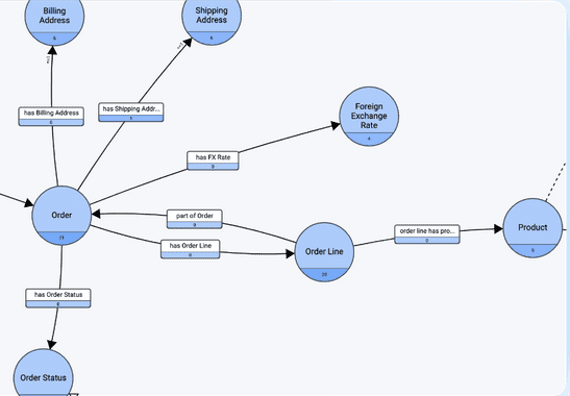
And more bridges between RDF/OWL are already here or are in development.
Finally, here is another bridge-building project:

SQL-PGQ means that SQL meets labeled property graphs, very likely here in 2021. This project is a step towards the development of a new property graph query language called GQL. This is also happening, as you read this, in the very same SC 32 ISO committee as SQL-PGQ and, most importantly, the very same committee as SQL itself.
Accountability
In April 2018, I made a little “crossover study” between Data Modeling, Information Management, and Data Science: Whither Data Modeling Education? (The Future of Data Modeling), blog linked here. I landed on predicting that the overlap between the three disciplines will become larger and larger. And, now — the future — certainly looks like one big mesh (look up the graph using the link up above).
Is anything stopping us from folding the three disciplines into just one (calling it information management as the winning term)? To be honest, yes, there is one thing: the issue of accountability!
The business driver for information management is record-keeping for a number of use cases.
It all started with ledgers and library cards. Then came the punched cards…

After physical media such as cards and tape came DBMSs, and 20 or so years later, record management systems. It is fair to say that the records kept in records management systems by information management professionals are, by design, reliable and consistent with reality. You can count on them to be true — that is what they are there for. And the activity is complex as this use case from clinical trials illustrates:

The data model is equally complex, with many time-depending concerns. Srini Dagalur, the author of the CTMS paper, which essentially is a primer for buyers of “Clinical Trial Management Systems,” stresses the following:
“As with any evolving process or technology, implementing a CTMS could result in challenges, such as:
- Data access issues, as data resides in multiple locations or there may be gaps in data collection (i.e., trial process-specific data might not be captured)
- Lack of mature Data Management capabilities to store current and historical data to aid data analysis
- The inability to respond to potential protocol amendments in a timely manner
- Poor quality and reliability of clinical operations data due to significant lag times between data entry and reporting and inconsistencies in reference data among various source systems feeding the CTMS.”
Here are some general comments on records management:

Note the emphasis (highlighting done by me) on “information,” “maintained,” “evidence,” and “pursuance of legal obligations or in the transaction of business.”
Is the business case described by AAIM above best suited for a records management system or a database management system? Here, at the beginning of the future, the databases used in Data Management are still not designed to guarantee accountable information (by design). Yes, SQL has some temporal support, and yes, there are data vault, anchor, and ensemble Data Modeling practices, but even all of that does not give a complete, accountable picture of information lifecycles. We are still missing important pieces such as retention, metadata changes, etc. And would it be difficult to do it? No, the records management tool vendors do it. DBMS vendors could also do it.
That would be the final, game-changing piece of DBMS functionality that cleans away the historical legacy of having Data Management alongside information management in two guilds.
2021 is the year of the creation of the new standard graph query language (GQL) that has the potential to be the next step after SQL. And which will interoperate with SQL and with RDF (cf. above). Needless to say that the GQL to-do list must include the accountability uses cases.
So, don’t let yourself be fooled by a seemingly peaceful context:

Realize that now is the time — just stick to the three recommendations: contexts, semantics, and accountability. Set them as our overall guidelines for 2021! 2020 has shown us that working together enables us to solve very large and very critical challenges. Happy New Year!