
Companies use a metadata repository to store and share information about data or metadata. Metadata repositories, once thought limited to databases or diagrams, have evolved sophisticated Data Architectures, driving businesses to transform the marketplace digitally.
Take the New South Wales (NSW) government’s Spatial Digital Twin, which went live in February 2020. NSW, an Australian state containing Sydney, envisioned a more efficient and better state infrastructure, including “major hospital upgrades.”
In response, Data61 created a 3D-model of Sydney, providing capabilities to see future changes and past construction. Magda, the system and power behind this digital twin, relies on a metadata repository to make tons of data faster to search and understand and to pull in even more data sets. From that metadata repository, hooked up to a data repository and data depository, Australians can digitally plan and build structures in real-time.
The enhancements to NSW’s capabilities would be the envy of most big businesspeople. Architects, emergency planners, traffic reporters, citizens, and more can use the Magda solution for unforeseen and valuable purposes, including solving complex infrastructure problems. But before thinking of a metadata repository to propel digital transformation, take a step back to understand what a metadata repository means.
Over the last 40 or 50 years, the metadata repository has grown more complex from concrete tables and database diagrams to multiple abstract architectures. This article explores metadata repository basics, from the database to the data architectures.
Metadata Repository as Database
Ask a person back in the 2000s to define a “metadata repository,” and they would’ve likely described it as a pretentious term for a computerized database containing metadata. Think of tables, tags, and text.
Metadata repositories got their start in software development over 40 years ago. Programmers needed metadata to understand what data a database had — and its structure and relationships — to improve Data Quality. Subsequently, engineers could construct, maintain, and update databases more efficiently. Often, the metadata repository meant a data dictionary, a document, and then a database describing all the data contained in an entire system.
As businesses increased the number of relational databases, searching through datasets became quite cumbersome. So enterprises consolidated and organized all the data through a data warehouse. The metadata repository also went through a change to better support data warehouse extract, transform and load (ETL) processes.
The metadata repository algorithms in ETL take all the metadata in a variety of formats: forms, a table, XML document/s, or a separate relational database. It then stores metadata in an organized format that can be accessed by data consumers.
On the technical side, the metadata repository updates information about the staging areas and the ETL processes. Developers get information about databases’ physical components, such as columns and rows, that make up the database.
The metadata repository also stores business metadata. This information describes data contents and conditions. Business metadata makes business terms consistent and collects them into a business glossary. Business metadata, provided by the metadata repository, reveal information about business data’s context and meaning, so that data consumers can better construct better reports and use data from the data warehouse.
Some sort of interface, like an information navigator, sits on top of technical and business metadata, allowing the user access to the metadata repository.

In this database or data warehouse conception, the metadata repository exists in one place, organized by a particular scheme. In a standard data warehouse diagram, the metadata repository is depicted as a centralized, single container storing all the system’s metadata, operating to the side along with other data warehouse functions.
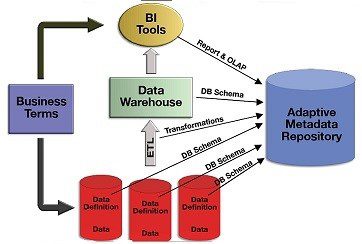
While the metadata repository as a database or container carries truth in some cases, the metadata repository has become much more than this.
Metadata Repository as Graph
Centralized metadata database repositories run into a problem. Technical and business metadata can be vast and combined with structured and unstructured data. This metadata does not conform well to a container.
For example, Lyft had multiple data stores and metadata repositories with a mixture of structured and unstructured data, accessible from SQL and NoSQL. Sure, a user can find column information or business information from a metadata repository hooked into one of the systems. But how would they know with which metadata repository to start and where to look first in Lyft’s Data Architecture?
Enter knowledge graphs, a type of ontology depicting entities and their relationships, or metadata about data points. Knowledge graphs paint a candid picture of data interactions and what data nodes do to each other. These pictorial representations require less computing power and reporting complexity. Property graphs, a type of knowledge graph, are composed of not only entities and relationships but also the entities’ attributes.

How does this relate to Lyft’s problem? Lyft used Neo4j to create a knowledge graph, aka a metadata repository, to find which data source was best to start. Want to know when a car will arrive to pick up a person? That kind of data discovery process happens through Lyft’s knowledge graph.
Consider databases and graphs to be metadata repositories.
Metadata Repository as Data Catalog
While knowledge graphs have shown potential for the metadata repository to find relationship patterns among large amounts of information, some businesses want more from a metadata repository. Streaming data ingested into databases from social media and IoT sensors, also need to be described. According to a New Stack survey of 800 professionals developers, real-time data use has seen a significant increase. What does this mean for the metadata repository?
Enterprises want metadata to show the who, what, why, when, and how of their data. The centralized metadata repository database answers these questions but remains too slow and cumbersome to handle large amounts of light-speed metadata. Knowledge graphs have the advantage of dealing with lots of data and quickly. However, knowledge graphs display only specific types of patterns in their metadata repository. Companies need another metadata repository tool.
Here comes the data catalog, a metadata repository informing consumers what data lives in data systems and the context of this data. Automation and discovery make the data catalog attractive by ensuring it keeps up with fast-moving data and its changes. Business and technical users can easily query the data catalog. As Craig Mullins in database trends and application noted, data catalogs deliver:
“Context to your organization’s data so that data users — such as data scientists, developers, data analysts, and other business data consumers — can find the data they need and understand the meaning of the data they are using.”
While it may seem the data catalog or metadata repository comes packaged from one place, it can be spread across multiple systems and tools, or federated. Accessibility may be available with one user interface or various APIs connected by a website.
In some contexts, pointing to the data catalog may not be enough to describe the fundamentals of a metadata repository. Technical people may need to know the systems and tools underneath the metadata repository. Business people may need to understand the complexity behind the scenes before purchasing one.
The Magda diagram of a data catalog, below, also shows a metadata repository.

Something like this architecture runs the NSW government’s Spatial Digital Twin.
Metadata Repository as Data Architecture
If adatabase, knowledge graph, and a data catalog can be labeled and used as a metadata repository, then which metadata repository represents the real one for all the enterprise’s metadata? Could it be a combination? At this point, miscommunications about a metadata repository can seem likely.
To bring a metadata repository to its basics, describe it as a type of Data Architecture storing metadata and making metadata accessible per business requirements. George Anadiotis, from ZDNet, notes to keep up with lots of data and meet regulations, like GDPR, metadata repositories need to span multiple clouds and include interchanges and APIs “to share and exchange” metadata. As companies become digitally transformed and manage their metadata, their future metadata repository will take shape more like the Magda data model above.
Due to this complexity, the NSW metadata repository took a couple of years to build before seeing a return on investment. Companies that want a sophisticated metadata repository tool need to have a lot of money and time available. Otherwise, it seems prudent to think about what type of metadata repository (database, graph, data catalog) fits best with a company’s business and data strategies, and architect that one.
Image used under license from Shutterstock.com