
Click here to learn more about Joe deBuzna.
Abandoning a data warehouse for a data lake may not be the answer.
Over the last few decades, we’ve seen an explosion in the use of data warehousing within the IT industry. It was all the rage for doing analytics and reporting. Data warehouses are popular because they allow companies to perform cross-analysis of their large amounts of data quickly and efficiently to support management’s strategic decision-making process.
However, in the last few years we’ve seen a disruption in the technology landscape, with the near-constant emergence and adoption of new technologies like Hadoop, NoSQL, and analytical appliances. These new solutions provide many benefits, such as cheaper storage, better performance for specific types of reporting, and support for new sources like sensor data, social media, geolocation, video, and web logs, which are unstructured or semi-structured in format.
This has unearthed some of the complexities surrounding data warehousing. The type of data entered into a data warehouse must be organized and structured to fit the data model, going through a transformation process to ensure that it’s cleansed and fit for purpose. In addition to challenges with the variety of data, we now also have a huge volume of data to contend with. For most companies, cost becomes a significant issue – not only with regards to hardware, but also with the workforce supporting the implementation.
With this in mind, it’s not surprising that companies might consider replacing their data warehouse with an enterprise data lake built around these new technologies. But we need to think carefully when asking: “Can I replace my data warehouse?”
Can I Replace My Data Warehouse?
From what I’ve observed in the marketplace and by talking to customers about their logical reference architecture, there is still a need for data warehousing. For all of Hadoop’s hype, it’s still in its infancy. To generate the kind of performance for doing complex queries and mixed workloads, Hadoop lacks the kind of features that makes data warehousing a must – for example, optimal indexing strategies, the ability to efficiently perform complex table joins with a range of terabytes of data, and an optimizer for determining the best path for queries.
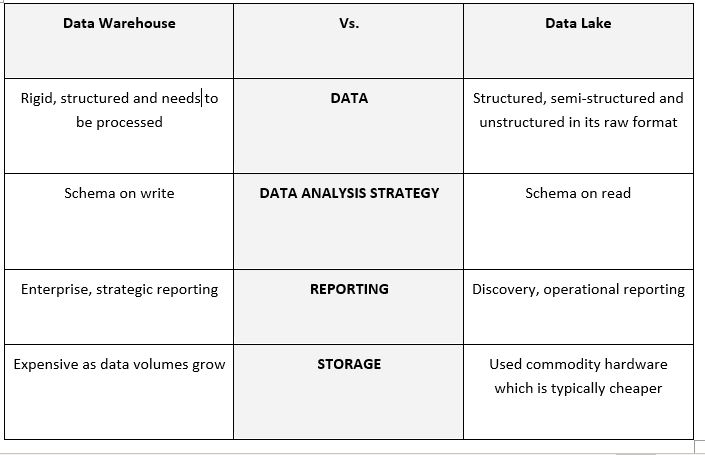
Advantages and Disadvantages of the Data Lake and Data Warehouse
Data Lake + Data Warehouse = Biggest Impact
Why choose one when you can have both? When you combine these technologies together, you eliminate all the disadvantages and reap all the benefits. Granted, not all companies will require everything in a single moment – what technology you deploy will be based on your end-user requirements and the data you’re pulling in. But what is fundamental in these architectures is the combination of a data lake and data warehouse working in a unified manner.

The old concept of having a staging area within a data warehouse is now replaced by the data lake, allowing for all forms of data to be ingested in their original format and stored on commodity hardware, lowering the cost of storage. This gives a business operational use of their raw data to perform discovery/ad hoc analytics, looking for patterns and finding the questions that the business doesn’t yet know to ask.
The raw data can then be massaged and refined to be loaded into the data warehouse and blended with data from other functions for analysts to perform more strategic reports, asking the questions the business already knows, like “What will my sales figures look like next year?”. As we ingest more and more data, more use cases open up for the data lake, such as customer 360, predictive maintenance, and risk/fraud detection.
By combining data lakes and data warehouses, we’ve already tackled two of the 3V’s of Big Data: volume and variety. What about velocity (and, I argue – variety and value)? That’s for another post entirely.