
Click to learn more about author Thomas Frisendal.
In my last blogpost Timely Concerns in Data Models, we looked at the basic challenges of dealing with time dependencies in Data Modeling. I promised to continue this quest by going over the history of these issues. How well have we actually solved these challenges?
So, hop onboard and enjoy a time travel of our attempts at handling temporality in data models.
CODASYL (1966)
The first official standard for database languages was defined by the CODASYL (Conference on Data Systems Languages), which was published it in 1966. It came out of Charles Bachman’s work with the IDS (Integrated Data Store) at GE. And gathered speed as IDMS on IBM mainframes in 1974.
Despite being date-unintelligent, the so-called network DBMS’s such as IDMS offered some useful techniques.
Here is a homemade IDMS “set occurrence diagram” showing instances of Employees, Jobs and Empositions:

I am not going to get into details, but the idea was to organize the data using two building blocks:
- The ”Recordtypes” such as JOB, EMPLOYEE and EMPOSITION above
- Named ”Settypes”, which connect the recordtypes with each other, as for example EMPOSITION, which lists the jobs held by employees by way of the two ”sets”:
- Job-Emposition (red), and
- Emp-Emposition (black)
We have two set types each with two occurrences because we have two Employees, each with two jobs. So what? Well the trick is that sets can be ”sorted” (which would be called ordered today). And if the ”sort key” was a date (disguised as a character string), you could order the set in date sequence (one way or the other). The set order for sorted sets is First->Next*->Last (closing the loop). So EMP-EMPOSITION could list the job positions in From date order per Employee.
There was even this alternative: Emp-Emposition could be ordered ”FIRST”
This means that new Emp-Emposition members (that is the term) were added at the front of the set, meaning that sequential reading from the beginning to the end was in date order. You could also order them LAST.
Although far from perfect, this was something. You could even do two separate sets, for Emp-Emposition, one for the transaction timeline and another for the valid timeline. ”Bitemporal” in 1966! – using pointer chains!
TSQL2 and TimeCenter (1985)
Already in 1985 Richard Snodgrass together with Ilsoo Ahn (in the ACM SIGMOD Record) proposed “Temporal Databases”. Together with a number of other academics he formed a TSQL2 Language Design Committee, which published a proposal for a temporal extension to SQL-92. TSQL2 was put forward in 1994.
In 1999 he published Developing Time-Oriented Database Applications in SQL which is a seminal work in the temporal database ecosphere.
TSQL2 was the first place, where the concepts of valid time and transaction time made their way into actual syntax; along these lines: “…VALID(X) OVERLAPS VALID(Y) AND TRANSACTION(Z) OVERLAPS DATE’now – 14 days’…”.
TSQL2 was entered into the SQL standardization process with the ambition of being part of the SQL3 standard in 1999. However, not least heavy criticism from relational theorists Hugh Darwen and Chris Date stalled that process. It was a debate about conformance with the relational model proper. TSQL2, stalled as it was, changed name to SQL/Temporal and waited some more years. (Except for at Teradata, who implemented it in 2010, but then the SQL standard moved on in 2011, cf. below).
Red Brick, Kimball and Dimensional Modeling (1990)
In 1986 Ralph Kimball founded a software company called Red Brick Systems, which in 1990 released a relational DBMS called Red Brick Warehouse. The product was optimized for heavy duty data warehouse and was based on SQL. The “secret sauce” of the Kimball approach was Dimensional Modeling, which hit the main street in 1996 with the seminal book The Data Warehouse Toolkit. I have had the pleasure and privilege to work with Red Brick and I was trained by Ralph. This changed my life as a data modeler (as I am certain it did for many of my peers as well).
Today Dimensional Modeling is the dominant modeling methodology for data warehouse and business intelligence. In relation to our temporal focus here, Kimball contributed the concept of “Slowly Changing Dimensions” (and “Late Arriving Facts”). Here is a simplistic example, where a Customer changes location data:
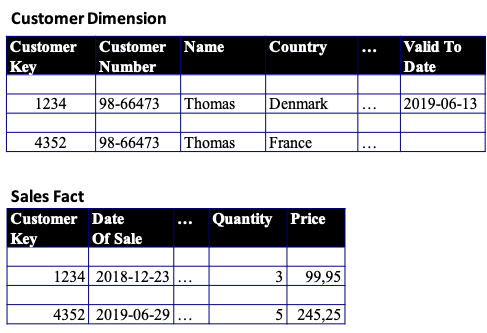
To keep track of e.g. changes in customer data, we introduce a “Valid To Date” in the customer dimension. This means that we may have more than one version of the customer in the database, but only one of them will be valid at any given point in time. This spills over into e.g. the sales fact by way of a convenient Customer Key (generated by the system), which connects the correct versions of the customer with the corresponding facts.
In reality it is a bit more sophisticated than this, but this is the general idea.
I think this is the first time that a “valid timeline” materialized in real data models on a broad scale, and it is also the first time that we see the contours of a persistence strategy based on INSERTs rather than on UPSERTs (INSERT and then UPDATE).
Groundbreaking indeed.
Relational Classic and Good Old SQL (1992)
The Classic Relational Model by (Messrs. Codd and Date) came out in 1969. The first “relational” DBMS based on SQL came out in 1974 (IBM System R prototype). But the first (1986) SQL standard did nothing for temporality. It was in SQL-92 that something happened in than the standard added date and time data types.
Of course, you could mimic the ”sorted sets” of IDMS by way of having dates being indexed and by way of ORDER BY clauses on the SELECT statements (maybe with a CURSOR on top).
You could have multiple dates on a table, but the SQL to express e.g. bitemporal queries was (is) prohibitively complex.
Alas, the urge to address the temporal issues accelerated in the nineties. In academia.
Timeseries DBMS (1999)
Although the first time-series DBMS came out in 1999, it is around 2012 that the concept picks up traction. The graph below shows number of new product introductions per year:
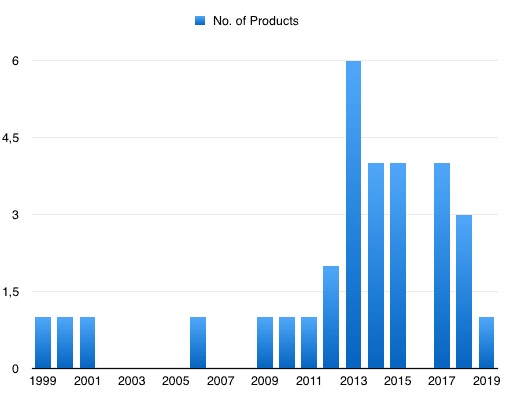
The above is based on the very useful site called DB-Engines, which now lists 31 time-series DBMS products. Generally, time-series DBMS’s are focused on collecting, storing and querying data with high transaction volumes. And there are some special requirements such as: Downsampling data, comparison with the previous record and joining time-series (on approximate timestamps or aggregations thereof).
Data Vault (2000)
Data Vault Modeling (DV) was conceived by Dan Linstedt doing modeling work for the US Government. Around year 2000 he went public with it, and it has gained quite some following in modeling-heavy contexts like government and finance. It is a clever way to use SQL-DBMS’s even in complex data models with requirements for extensive support of temporality and with good performance in loads of data warehouse data.
Here is my attempt to explain DV in one simple concept map:
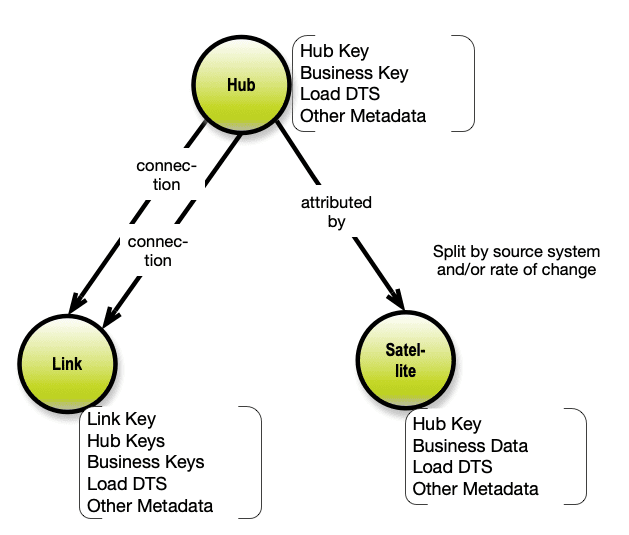
The concept model above represents the logical layer of a DV. Hub’s represent the core “persona” of the business object types. Could be Persons, Products etc. and the hubs primarily contain the business keys of the business objects. The properties of the business objects are split into “satellites”, which contain the properties. Frequently satellites are split because of different source systems and/or load patterns (DV is a data warehouse thing). The relationships are represented as “links”. The links can, in reality, be of different kinds.
The physical level is slightly more complex. End-users are not seing the DV data model, but access the data via multidimensional views or data marts.
Note the omni-presence of “Load DTS”, date-time stamps of load. DV is more and more handled as “insert only”, not least for performance reasons. This also lays a good foundation for temporal queries taking into account not only business date/time, but also the Load DTS’s. Finally, it also supports evolving content over time.
Temporal and Relational (2002)
In 2002 Hugh Darwen and Chris Date together with Nikos Lorentzos published a new book called Temporal Data and The Relational Model (Morgan Kaufman). The book was intended to be used as textbook for tutorial purposes when “describing a truly relational approach to the data problem” (text from the back cover). It is based on the language “D”, which is their bid for a proper relational data language.
Despite the fact that I liked D a lot better than SQL, D never made it to Database Main Street. SQL was still king of the road.
Ontologies and the Semantic Web (2006)
This rather important part of the database and modeling realm does not always get the attention it deserves. The RDF standard (and related DBMS’s) is one of the workhorses of (web-oriented) data architectures. With regards to temporal, I know about the “Time Ontology in OWL” (cf. W3C), which first appeared around 2006. I have not worked with it myself, but the impression I get, is that it is focused on temporality of geolocations and that concepts such as valid time (for bitemporality) and time-series are currently out of scope.
Temporal Modeling and ORM (2008)
I have been following the “Fact-oriented Modeling” community for many years. It actually goes back to the seventies, and its’ best known incarnation is called ORM (Object-Role Modeling). Today most practitioners prefer to call it Fact-oriented Modeling. It is used on the conceptual level. The visuals come in different flavors, but they all look similar to this:
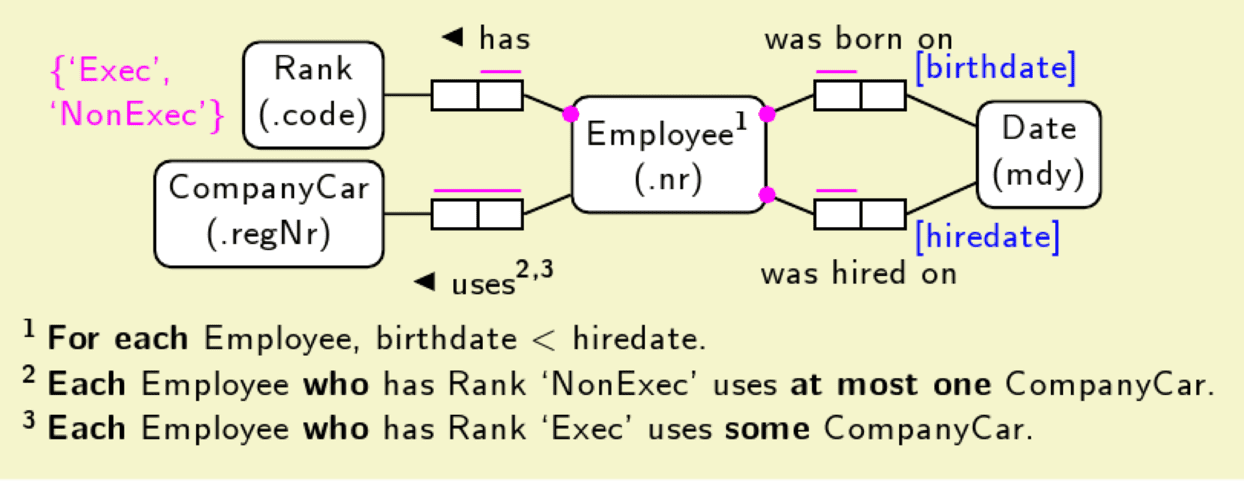
(http://bit.ly/2adndNS By Jakob Voss, Public domain via Wikimedia Commons)
Note that the Date object is related to the Employee (number) in two different roles. NB (an important observation): Temporality must be applied to the lowest level of detail.
I have placed this in the year 2008, because in that year, Terry Halpin published a conference paper with the name Temporal Modeling and ORM. It is an excellent overview of the academic history of temporality across all major data model paradigms.
Recently, the fact-oriented modeling tool Casetalk, proposed that you could use a little clock icon to denote temporal aspects of facts. Good idea, but why not a calendar icon?
Anchor Modeling (2009)
Anchor Modeling is similar to Data Vault in some ways, but it certainly also has some other ideas of its’ own. It sprang out of real-life use cases implemented by Lars Rönnbäck and Olle Regardt in Sweden, and today it is supported by research at the University of Stockholm. Lars and Olle took it to the public in 2009.
Here is a simplified “one-pager” concept map of Anchor Modeling:
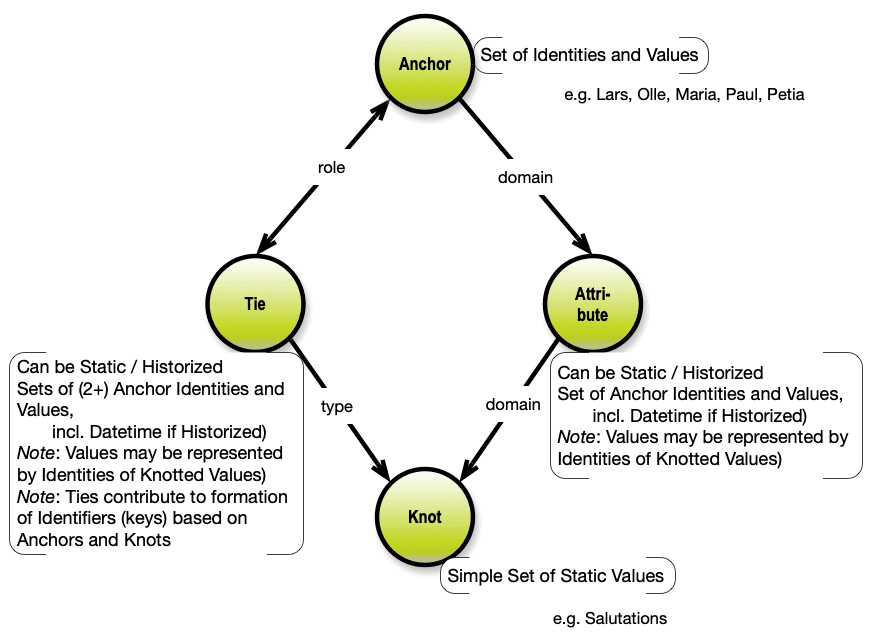
Anchors are the business object types, Ties are the relationships and Attributes are properties of Anchors. Knots are practical for handling simple sets of almost static codes and descriptions such as countrycodes and –names etc.
The approach is open source and works well with heavily (6 NF) normalized data, and has good temporal qualities. Like DV, Anchor Modeling shows what it takes to do temporal modeling on top of ordinary databases – adding 6NF to the equation.
There is a fine website for Anchor Modeling, and there you can even find a free modeling tool!
SQL (2011)
The CS Dept. at the Univ. of Arizona has summarized how TSQL2 (SQL/Temporal) finally found its way into the SQL standard: TSQL2 and SQL3 Interactions.
The following is a shortened version of their notes:
ISO/IEC 9075, Database Language SQL:2011 Part 2: SQL/Foundation, published
December 15, 2011, includes:
- “Application-time period tables” (essentially valid-time tables)
- Single-table valid-time sequenced insertions, deletions, and updates
- ”System-versioned tables” (essentially transaction-time tables)
- “System-versioned application-time period tables” (essentially bitemporal tables).
The same document mentions around 10 products, which have implementations of (parts of) this standard. Here is an example of an ”as-of” query based on a Microsoft SQL Server Systems Versioned Temporal Table:

(Downloaded from the MSDN documentation on 2019-06-14).
Although this temporal SQL standard has been around for some years now, I have not seen many actual applications of it in working systems. I would like to hear about your experiences; please send them to info <at> graphdatamodeling.com. Thank you!
Ensemble Modeling (2012)
In the data warehouse space Kimball approaches dominated the user-facing data. In the central data warehouse, data vault progressed, together with some anchor modeling and some other variations over the common pattern.
This common pattern got a name in 2012 when Hans Hultgren published a blogpost about Unified Decomposition™. In order to keep up with serious challenges such as:
“Flexibility, adaptability, agility, and generally to facilitate the capture of things that are either interpreted in different ways or changing independently of each other. So we want to tie things together at the same time as we are breaking them out into parts.”
This greatly helps with temporality, of course, (and with integration, and agility and insert-only loads and more).
Look at the concept models up above for Data Vault and Anchor Modeling, and what you also see in them, is the metamodel of the Ensemble Logical Modeling pattern:
“A core business concept, Customer for example, is represented (DW-wise) as a decomposed “Ensemble” of its Hub, its Satellites and its links directly to/from the concept based on the business key.”
Hans Hultgren named the approach Ensemble Modeling™ in his 2012 book on Agile DW Development. Being a DV person, Hans Hultgren described it in DV terms, but it also applies to Anchor Modeling as well as other 6th normal form approaches. 6NF (in relational theory) was indeed ”…intended to decompose relation variables to irreducible components.” (Quoted from the Wikipedia reference re. 6NF just above).
Tom Johnston: Bitemporal Data Theory and Practice (2014)
Tom Johnston decided to give the whole issue of bitemporal data a detailed overhaul an published a well-researched and well documented book about this in 2014. It is a great book having a solid theoretical part and an as solid practical part. Space does not permit me to into details, so if you are faced with these challenges, this book is a good choice. Here is a very short collection of tidbits: Both the semantics and ontological aspect of the relational model (and temporality) is specified (for the first time) in detail. Contains an extensive, logy” annotated glossary and a handy notation paradigm. He prefers “state time” and “assertion time” as the best terms. Assertions are sort of enveloping the relational model with a temporal layer. Selected new terms: “Temporal primary keys”, “referents and RefIDs”, “temporal foreign keys”, “STATE INTERVAL”, “Relational Paradigm Ontology …
Highly recommended for hard-core bitemporal projects based on SQL databases.
Anything New After 2014?
Well, except for ever more time-series DBMS products there is only one thing, which springs to mind: Lars Rönnbäck, best known for Anchor Modeling, is working on ”Transitional Modeling”, which broadens the perspective from data to context and from time to also realiability. It is work in progress. Look up his formal, in-depth paper: Modeling Conflicting, Unreliable, and Varying Information. His most recent post on this project is this: Rethinking the Database.
I will do my best to make a concerted distillation of all this and add my own thoughts about good and necessary ways of doing temporal data modeling in better ways than what is possible today. That will be my last blogpost this summer. Stay tuned!
Next: Going Forward, But How?
With this, allow me to make a transition to my forthcoming 3rd blogpost in this series (August 2019, I presume) on future perspectives on temporality in Data Modeling.
Until then: Enjoy the seasonal vacations!