
Click to learn more about author Thomas Frisendal.
Using Concerns to Navigate Data Architectures
Welcome to 2019! This is the year that offers us a unique opportunity to re-architect the way we think schemas, data models and Data Architecture. We do indeed need to do some things better.
The real world is full of concerns, some of which are more or less contradictory. One good example is the schema life cycle discussion: Schema first? Schema last? Schema-less? Apparently mostly a technical level issue at first sight. But then again, some business needs are only answered by way of humongously rigorous data design. Take compliance reporting in the financial sector, for example. Yet, other business opportunities are not really depending on strong, up-front schema designs. Agile, step-wise schema evolution as an ongoing process, definitely has its attractions.
The unique opportunity in 2019 is the emergence of a standard graph query language for property graphs (see https://www.gqlstandards.org/home). This includes considerations for schema support. The challenge is: Can we, in 2019, architect a schema architecture that fits most contexts, business situations and development styles?
Let us sail out into the stormy seas of 2019 by first exploring the foundations of modern Data and Information Architectures.
Full Scale Data Architecture
An informal European organization of data architects called Full Scale Data Architects has come a long way of on fitting data architecture into the realities of today. Here is the groups’ mission statement as expressed by one of the founders, dutch Martijn Evers:
”As a start Ronald Damhof and myself are trying to make Data Architects come to grips with the new reality of data, and how to get control back. For this we started a movement for more Full Scale Data Architects to help us combat the ever increasing data-tsunami. For raising awareness, we postulated 10 commandments for the (aspiring) Full Scale Data Architect. Join us on our mission to combat data entropy”.
An overview of their meta architecture can be seen here:: https://secure.meetupstatic.com/photos/event/5/e/1/4/600_467724084.jpeg:
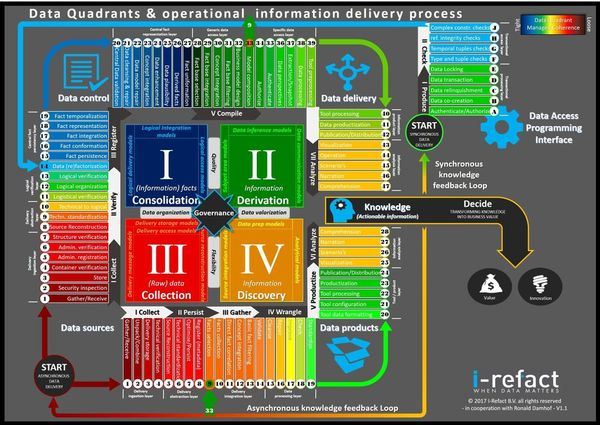
More on Facebook: https://www.facebook.com/FullScaleDataArchitects/, and on Meetup: https://www.meetup.com/Full-Scale-Data-Architects/.
The key to understanding their approach is the 2 by 2 data quadrant matrix depicted above. You can read more about that here: https://prudenza.typepad.com/files/english—the-data-quadrant-model-interview-ronald-damhof.pdf.
In essence the four quadrant unite two competing dimensions:
- Data control vs. data flexibility
- Data delivery (push) vs. data consumption (pull)
Here is my personal “artistic impression” of the essentials:

I particularly like their visual metaphor of the control vs. flexibility dilemma:

You’ve got to control the attacking bull by firm grips of both horns. And you can change the course somewhat, but only at the cost of either lower quality or lower flexibility.
OK, so now we (with good help from the Dutch) have identified the meta characteristics of full scale Data Architectures. What, then, determines which things go into which quadrants?
We need to go all the way back to 1974 to be kindly reminded by the (Dutch) computing science pioneer Edsger Dijkstra about the importance of “the separation of concerns” in his “On the Role of Scientific Thought”.
Multi-Level Concern Architectures
Edsger Dijkstra was working together with prof. Peter Naur on the European Algol 60 project. Peter Naur was my professor, when I enrolled the University of Copenhagen in his second year of having the very first chair as professor of the new field called computing science at the university. I remember prof. Dijkstra quite well. So I am thankful to Martijn Evers for reminding me of the separation of concerns philosophy. I will let Martijn explain the roles of concerns in Data Architectures:
“The number of new “data/information” modeling ideas, approaches and designs are proliferating, spurred by technological and business needs. and as architects we need to get a grip on this new dynamic… This was my cue to change the game. Instead of designing yet another variety of Data Vault, Anchor Modeling or Fact Based Modeling I wanted to turn things around. Not the modeling technique/approach should have the center stage, but their underlying concerns. The varieties of modeling are endless, but the concerns they try to manage are not… Because we see a movement where on the one hand we have austere and lean modeling approaches that don’t function on their own, but just focus on a select set of concerns, and on the other hand we see rather dominant modeling approaches that try to do everything, but not very well. A one size fit’s all is becoming less and less realistic. Also, data modeling architecture has always been seen as very static, but that is also changing rapidly. We can’t fix it all in one go, so gradual change in the way organizations do data modeling/organization is becoming more important. This all leads me to believe that an agnostic approach to understanding and managing ‘data modeling’ is becoming a necessity”.
In other words, we have to get the concerns out into the light of day. And we have to understand how they (might) depend on each other. This will give us a “road map” of several different routes that you can take to solve some specific data delivery challenges.
In my (2016) book about Graph Data Modeling for NoSQL and SQL. I developed a set of requirements for Data Modeling across the board. I have now made sort of an amalgamation with Martijn Evers’ concerns, which, like mine, are multi-level. I propose these 3 levels:
- Business level concerns
- Solution level (logical level) concerns
- Implementation concerns
Let us look across those 3 levels in the context of schema design. Note that property graphs (the subject area of the forthcoming standard GQL standard) are very close to the business concept level (from white-board to database can be very easy), which means that all 3 levels are relevant also in the (not so narrow) context of schema design for graphs.
With respect to the data quadrant matrix most (but not all) concerns have a natural “home” in one of the quadrants (indicated in the list below). Some concerns are relevant in two or more quadrants.
Also note that there are some “innate inheritance” for the types across the 3 levels.
General Concerns
- Business facing terminology should prevail at all representational levels (possibly with some syntactical variations), Q1, but manifested in all 4, as relevant
- Set algebra support at all levels (a favorite hobby-horse of mine), Q1-4
- Schema first; is a valid concern in many business areas requiring rock-solid, validated, governed, business-approved definitions and data of highest possible quality, Q1
- Schema less; is also a valid concern in many business areas requiring here-and-now loads of data having meaning and structures, yet to be discovered, Q3, Q4
- Refinement; (thanks to Martijn for this formulation of an important concern) – … many assume that all models have the same level of refinement, i.e. that transformations are semantically equivalent, or even isomorphic. But some models might contain different levels of abstractions. For this the model needs to become a 3D matrix. Traveling in this cube is needed to represent the abstraction and refinement that we see in actual data/information modeling. Q1, Q4
Business Level Concerns
- Business terminology, incl. definitions, should be enabled, Q2
- Basic dependencies (relationships between concepts, both functional dependencies and structural dependencies), Q1
- Business friendly elicitation and visualization, the business facing level must be built on the concept model paradigm (another favorite hobby-horse of mine), Q1, Q2
- Minimal effort business concept model; short “path from white-board to first-cut schema” and it should be easy to maintain, Q3
- Solution independence, the concept level schema details should be derivable from the solution level schema details, Q1
- Standard visualization paradigms, Q1-4
- Standard concept types (Q1):
- Business objects
- Properties of business objects
- Sample values (for illustration purposes).
- Standard relationship types (Q1):
- Named, directed relationships with simple cardinalities
- Directed style for relationships between business objects
- Undirected style for relationships between a business object and its properties.
- Generic data types (number, string, date, amount …), Q1
- Simple business rules written out as textual comments in the schema, Q1
Solution Level Concerns
- Platform independence, the solution level data schema details must be independent of the data store platform, Q1
- Solution derivation; a solution level schema should be derivable from (a subset of) the business concept schema; some concepts become logical business objects, whereas other concepts become properties of those business objects, Q1, Q4
- Stepwise solution refinement; A solution level schema should be gradually and iteratively extendable (with design decisions), Q1, Q3
- Graph
and subgraphs (incl. sets), Q1-4
- Graphs (a collection of nodes and relationships)
- Subgraphs (subsets of graphs, for example by way of set algebra)
- Sets (set algebra)
- Uniqueness; constraints like e.g. concatenated business keys should be definable, Q1
- Identity; Identity is closely related to uniqueness, support for solution level details (decoupled from the implementation details) should also be definable, incl. support for identifiers and surrogates; cf. also the next, Q1
- Updatability; ensure that all functional dependencies have been semantically resolved without dangling properties and relationships, and that all identities are in place (this concern can be relaxed in some contexts), Q1
- Schema-controlled audit trails and lineage; the solution level schema should be able to contain technical auditing data, Q1
- Temporal integrity, Q1, Q2
- Time series aspects, Q1, Q2
- Property
graph types (Q1):
- Generic nodes (otherwise typeless)
- Business objects (labeled concepts)
- Multitype nodes
- Properties of business objects or type-less nodes (properties are concepts, which share the identity of the business object that owns them)
- Named, directed relationships with precise cardinalities, where applicable
- Mandatory properties; should be definable, Q1
Physical Level Concerns
- Intelligent ingestion; inferred or implicit types, load of generic node types, labeled node types and relationship types without explicit up-front schema definitions (but with after the fact physical schema details available), Q3, Q4
- Easy mapping of transformations; for instance: physical level schema details should be easily mapped back to the solution level schema details, for example by way of visualization of abstractions etc., Q1
- Complete lineage; easy backtracking from the physical schema to the solution schema and further on to the business concept model, Q1
- Constraint facilities (to support the solution schema details), Q1
- Indexing facilities for identity and uniqueness and ordering, Q1
- Temporal integrity support, Q1
Consider all of the above concerns as an initial bet. There are certainly things to discuss!
Different Routes to an Eventual Schema
Consolidated Means lots of Concerns!
As you can see from the list above, tight governance (Q1) equals many concerns; 2 out of 3, in fact. And there are bound to be quite a few dependencies between them.
There are only 2 concerns, which are not found in Q1:
- Schema-less, and
- Intelligent ingestion
They are somewhat connected and are sort of antagonistic to the idea of tight governance.
Some concerns are “global”: Set algebra, visualization paradigms, stepwise refinement, graphs and sub-graphs as well as time-series.
There are also concerns, which apply to a couple of quadrants.
Concern Dependencies
I made a quick first round of looking at dependencies between concerns. Some concerns require the presence of other concerns:
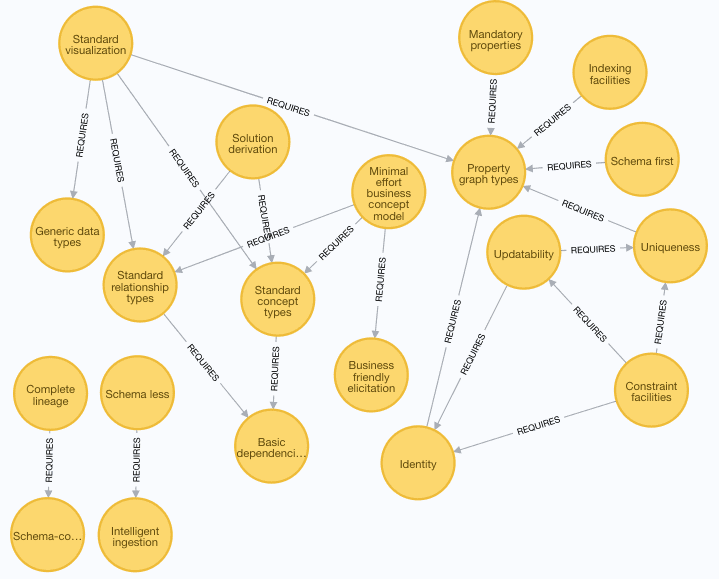
I left these concerns unconnected to any prerequisites (for the time being):
- Business facing terminology
- Business terminology
- Easy mapping of transformations
- Graph and sub-graphs
- Platform independence
- Refinement
- Set algebra
- Solution independence
- Stepwise solution refinement
- Temporal integrity
- Time series
“Prerequisites” in the sense that the “schema designer / user” has to specify something addressed by a concern.
I have almost certainly overlooked a few things; time will show…
Some possible scenarios for working with the schema
We are now able to answer questions about how the to-be-developed property graph schema facility can be employed. Just look at the dependency graph up above.
Can we work schema-less (without an upfront schema definition)? Yes, we can, so long as the “Intelligent ingestion” is in place.
Can we work schema first? Oh yes, we can.
What are the minimal requirements of working schema first? Well, we need to be able to specify schema details, which are property graph types. Add to that that there are several other areas of concern, which can be covered by the schema language, according to the actual context. The concerns are grouped by type of governance and by type of delivery of “schema products”.
Must I embark on almost defining a business glossary (terminology definitions)? No, that particular concern is not required by any other concern.
How do I make a business concept model inside the schema in an easy manner? Well, I must be able to map to standard concept types and standard relationship types. Those two, in turn, require that we can name the basic dependencies, which become discriminators for creating properties and relationships. It also requires some business friendly elicitation facility, which in my opinion is visualization (of concept models), but that concern is left optional, at least in the meta architecture depicted in the graph above.
Can I use the schema last approach? Yes, the design is concerned about lifting schema details upwards from physical to logical solutions and from there to the business facing level.
Dealing with Complexity and Contradictions
The forthcoming property graph schema standard that I have chosen as scapegoat for demonstrating the most important parts of the full-scale architecture thinking, is both complex and has a number of contradictory concerns. The full scale Data Architecture meta framework, starting off with the four quadrants of the two hard dimensions (governance and delivery styles), is a good framework for architecting even a thing like a schema language to be used in many different contexts and in many different development styles.
I am deeply grateful to Ronald Damhof and Martijn Evers and the other members of the Full Scale Data Architecture community for sharing their thoughts and experiences. And I look forward to learn more from their side. Keep the good stuff coming, alstublieft!
Note to readers who don’t speak Dutch: “alstublieft” is Dutch for “please”!