 by Angela Guess
by Angela Guess
Darren Cibis recently wrote in DZone, “With the current move to cloud computing, the need to scale applications presents itself as a challenge for storing data. If you are using a traditional relational database you may find yourself working on a complex policy for distributing your database load across multiple database instances. This solution will often present a lot of problems and probably won’t be great at elastically scaling. As an alternative, you could consider a cloud-based NoSQL database. Over the past few weeks, I have been analysing a few such offerings, each of which promises to scale as your application grows, without requiring you to think about how you might distribute the data and load.”
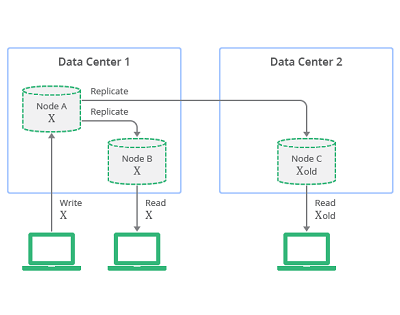
Cibis goes on, “Specifically, I have been looking at Amazon’s DynamoDB, Google’s Cloud Datastore and Cloud BigTable. I chose to take a look into these three options because we have existing applications running in Google and Amazon’s clouds and I can see the advantage these databases can offer. In this post, I’ll report on what I’ve learned. Firstly – and most importantly – it’s necessary to understand that distributed NoSQL databases achieve high scalability in comparison to a traditional RDBMS by making some important tradeoffs. A good starting-place for thinking about this is the CAP Theorem, which states that a distributed database can – at most – provide two of the following: Consistency, Availability, and Partition Tolerance. We define each of these as follows: Consistency: All nodes contain the same data; Availability: Every request should receive a response; Partition Tolerance: Losing a node should not affect the system; Eventually Consistent Operations.”
photo credit: DZone