
Few IT applications are truly grass roots. Rather most new applications are intended to replace or complement existing applications. As a result, we often find ourselves working with legacy databases. This article is based on 50 legacy databases that we’ve studied over the years. In our experience about 20% of database designs are clean and problem free. The remainders have design errors. This month we discuss primary key and foreign key errors. Next month we’ll address other design errors.
Primary Key Errors
A primary key is a unique combination of attributes that is used to preferentially access each record in a table. None of the attributes can be null. The combination of attributes should be minimal. A table has at most one primary key and normally should have one. On occasion, a table will lack a primary key, such as tables that are computation artifacts.
We find it surprising that databases have primary key errors because primary keys are one of the most basic aspects of constructing a schema. In practice about 20% of databases violate primary key rules. It would seem that developers should be using data modeling tools. And data modeling tools make it easier to properly define primary keys. Nevertheless developers are making primary key mistakes.
Foreign Key Errors
A foreign key is a reference to a unique identifier. Theoretically the reference should be to a primary key and not some other unique key. That is the whole point of a primary key, being the route for preferred record access. Data modeling tools can generate code for keeping foreign keys consistent with their referents.
Unfortunately, in practice many databases have foreign key problems – about 50% of databases, we’ve found. Here are some common foreign key problems.
- Dangling foreign keys. A foreign key points to a primary key that isn’t there. This is especially odious. The database is supposed to be a store of information, but with dangling keys the data is corrupted and nonsensical.
- Reference to a unique key other than the primary key. There’s no benefit to this. This is a poor development practice.
- Informal linkage between tables. For example a Job table may refer to a Company table by embedding the company name in the job title.
- Mismatched data types. The data type of the foreign key does not match that of the primary key. Clearly this is sloppy. But it also prevents a database from declaring referential integrity to keep a foreign key consistent with its referent.
- Overloaded foreign keys. The diagram shows a simple example. The Value table refers to Entity_Type via two routes. Both paths must refer to the same Entity_Type. This constraint should not be enforced by consolidating entity_type_name1 and entity_type_name2 into a single attribute. Rather it can be enforced with a SQL check constraint.
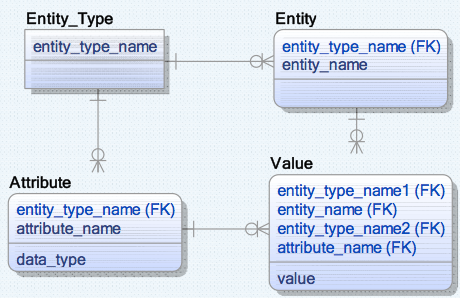
- Partial foreign key reference. A foreign key must refer to an entire primary key, and not just part of it. Consider a Department table with a primary key of company_name + department_name. An Employee table should only refer to both attributes and not to department_name alone.
- Lack of foreign key indexes. By definition a foreign key refers to a primary key and that reference will only be efficient if the foreign key has an index. This is not a flaw in database structure. It is serious nonetheless as queries often traverse foreign-key-to-primary-key paths and users expect reasonable performance.