
The road to better Data Quality is a path most data-driven organizations are already on. The path becomes bumpy for organizations when stakeholders are constantly dealing with data that is either incomplete or inaccurate. That scenario is far too familiar for most organizations and creates a lack of trust in Data Quality.
While most organizations are looking for ways to improve, you need to remember that high-quality data is a journey and not a destination. However, that can be a hard pill to swallow. It’s a reality most companies have to accept as the sheer volume of data being processed and analyzed increases over time.
Data is an organization’s most important business asset and is bound to contain errors at some point, despite having solid tools and procedures in place to prevent them. Low-quality data in your data warehouse decreases the value of that data to your company. To increase that value, your organization should implement the following set of best practices into your Data Strategy.
1. Automate Data Monitoring
Setting up automated data monitoring ensures your team will proactively catch Data Quality issues before your end-users do. When you automate data monitoring, issues are much more likely to be detected and addressed, which slowly builds trust in Data Quality with users over time.
One way organizations are automating data monitoring is by integrating it with a tool like Slack. Alerts can be sent out that there was an anomaly within the data, and the data team can then assure the rest of the organization they are on top of it and update stakeholders in real time as they diagnose and fix the problem.
When it comes to data monitoring, you can break it down into three types:
- Assertions: With assertions, you are validating your business assumptions about the data. For example, a company might need to validate that numeric data in one table falls within an expected range. Two great tools that help you with testing your assertions are dbt and Great Expectations.
- Metric monitoring: With metric monitoring, you define metrics such as the number of rows added to a dataset daily and track them with machine learning (ML). But why would you want to track them with ML? Metrics tend to carry a lot of inherent noise, and simple threshold rules that are used in assertions perform poorly.
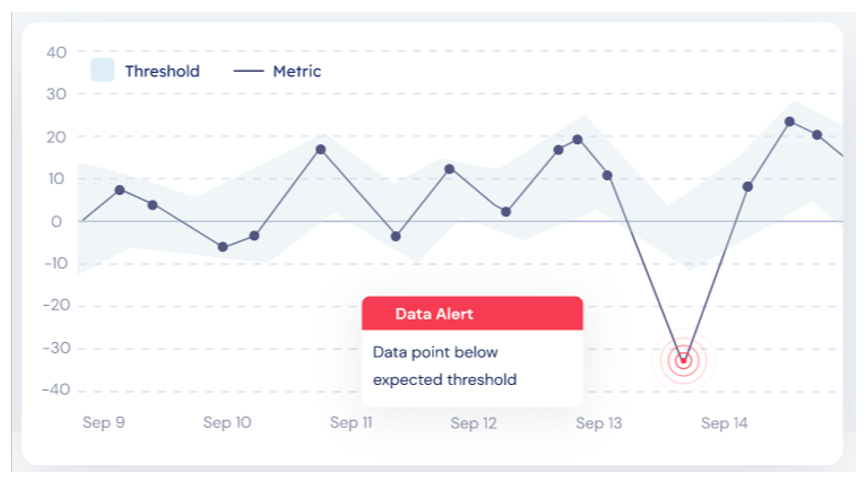
- Anomaly detection: As opposed to metric monitoring and assertions, you do not define anything in this case, as the systems learn how your data usually behaves and tell you when something is wrong with your datasets. This can be tricky since it is prone to high noise.
2. Improve Change Management Process
Improving your change management process is an often overlooked but key aspect of improving the quality of your data. Here are three things you should be doing to improve your process:
- Version-control the code that transforms and processes the data. By doing so, engineers and analysts within the organization are able to track changes made to code and collaborate together on projects with the ability to branch off and merge code when it is ready for production.
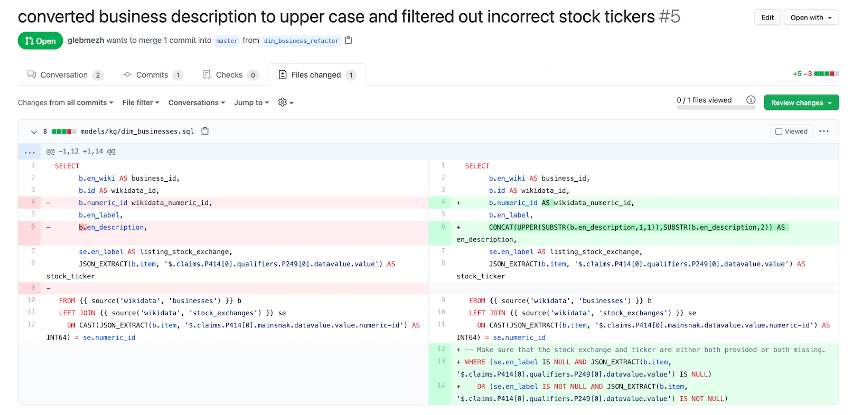
- Make sure the impacts of changes to your data are understood by everyone that works with it: Data lineage and Data Diff are two key tools that enable impact analysis. Data lineage easily allows you to see who and what are going to be affected by the change by showing the dependencies between BI assets, columns, and tables in your data warehouse. This makes it easier to give other people in your organization a heads up that your change will impact them or their dashboards before you make the change.
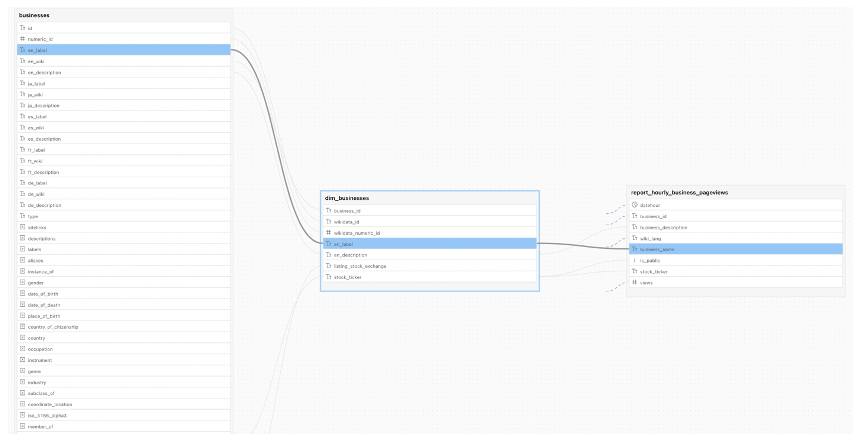
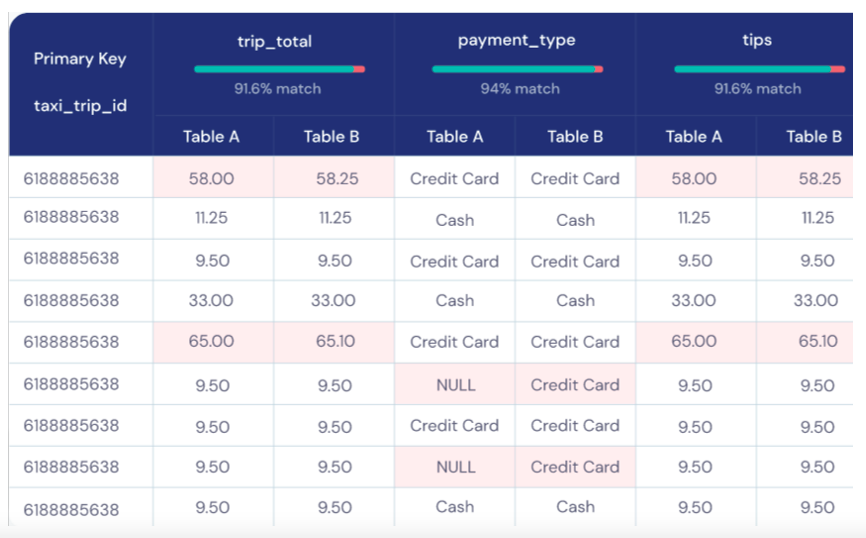
Data Diff lets you easily compare datasets (for example, production to development versions) to see how changes made to source code will impact your data, allowing you to proactively troubleshoot if needed.
- While reviewing code can be a cumbersome process, it is crucial to have a clear code review process in place, ensuring appropriate approvals and due diligence are done before deploying code into production: Failure to do so could not only cost your employees time with hunting down bugs but could also be costly to your organization if there are periods of time where data is not accurate.
3. Facilitate Data Understanding
In order for stakeholders to get the most value from the organization’s data, you should make sure that stakeholders understand all aspects of the process and data.
Organizations are facilitating data understanding in three ways:
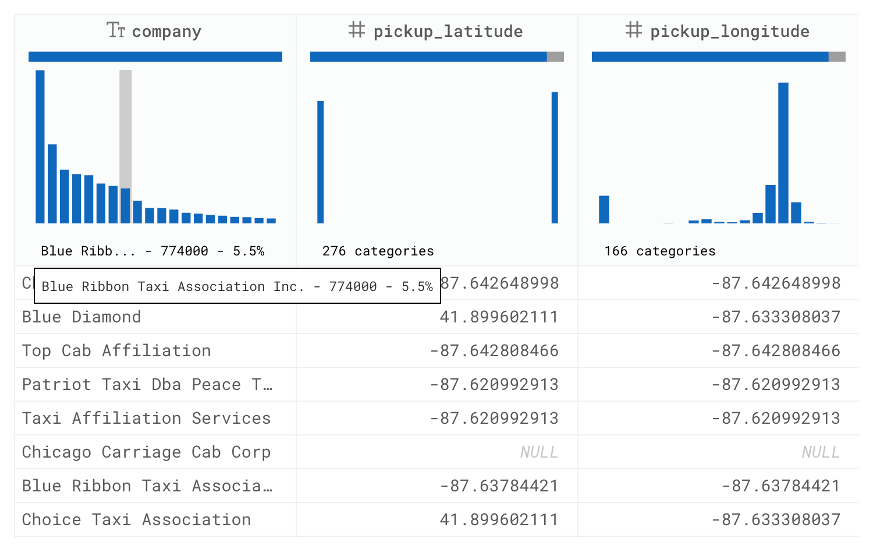
- Data profiling helps users see how data works via distributions, basic quality metrics (e.g., completeness % of NULL values), uniqueness, etc. This is helpful for developers who need to understand the data they will be working with before using it for analysis and reporting purposes.
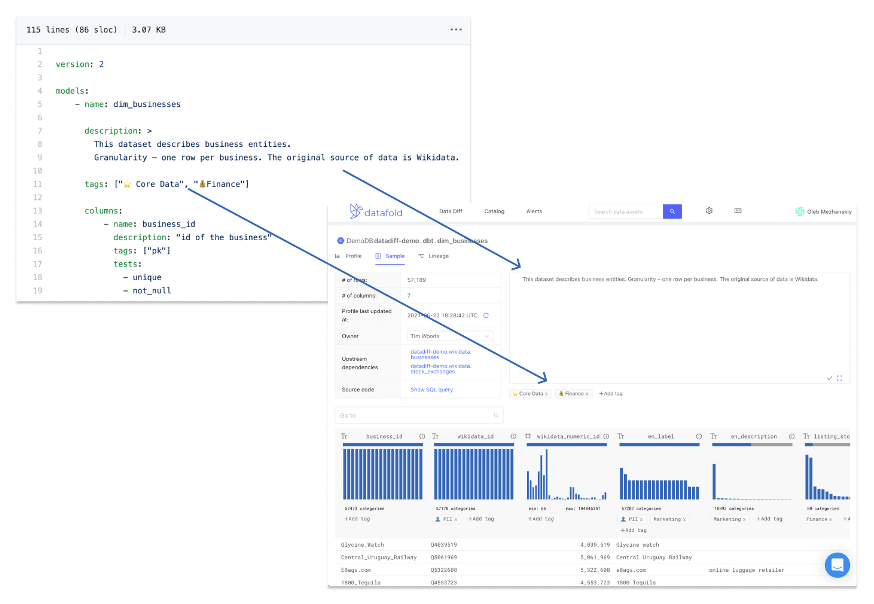
- Creating and maintaining data documentation for your data sets is critical as they provide business-specific context to the data available to stakeholders. The ideal scenario is that your documentation lives alongside your code with a user-friendly UI that has the capability for full-text search. Why would you want your documentation to live alongside your code? By doing so, documentation is now part of the analytic workflow and can be updated in real time. This means it is no longer an afterthought and the information in the documentation actively reflects all data sets. A product that does this well is dbt, as it allows to cleanly embed table and column descriptions and tags in the schema definition file. That documentation can then be easily synced to a data observability tool and augmented with interactive data profiles.
- When it comes to data infrastructure, lineage helps with tracing data through a series of transformations from raw sources to BI and ML applications. While some data transformation frameworks such as dbt provide table-level lineage out of the box, data developers often need a finer, column-level lineage view that is available through specialized data observability tools. It also helps with assessing the importance and trustworthiness of a given data source, allowing you to see who is using it (similar to Google’s search engine page ranking ability).

4. Build a Culture Around Data Quality
Of course, one of the most efficient ways to improve your organization’s Data Quality is by building a culture around it. However, this is often easier said than done for organizations, as various factors come into play when completing this task.
Here are some questions you should ask yourself when you are creating a culture around Data Quality:
- How will you get upper management to buy into the idea that they need to care about Data Quality? And, once you do so, what steps will they take to lead the initiative from the top-down?
- How will you educate employees on the importance of Data Quality and the role they play within the organization for achieving high-quality data?
- What training and tools will you consider for your employees to make their jobs easier when it comes to maintaining Data Quality? Note: Tools should live alongside code and be embedded in their engineering workflow so it is not forgotten by employees.
- How will you structure data teams inside your organization to allow for collaboration?
- If everyone owns something, then no one owns anything, which is why it is important to establish roles and responsibilities for data team workers. However, how you determine who owns what tool or responsibility varies by organization.
How will your organization keep data privacy in mind while keeping up to date with data compliance changes? What does your organization have in place for Data Governance and Data Management?
Start Improving Your Data Quality Today
Improving your organization’s Data Quality won’t happen overnight, and what works for one business might not work for another. Regardless, improving your Data Quality is not an easy task but is very worthwhile. Given the complexity of the modern data stack, challenges will always remain when dealing with Data Quality, but minimizing the effects of those challenges by investing in the right tools and following the right procedures can aid your organization.