
One of the newer data buzzwords is “data debt.” Actually, it is approximately 10 years old, and it became popular ever since agile people realized that postponing things creates not only technical debt, but certainly also data debt. Will we, in 2023, be better at not creating so much data debt, and will it be because we can come to know stuff easier (knowledge graphs) or will it be because of being able to guess stuff easier and more reliably (ML)? Or both?
Let us first set a framework for looking at the issues. In January 2021, I posted this: Three Game-Changing Data Modeling Perspectives.
Since then the interest in applying ML and AI to “DataOps” in the analytics space has risen to new heights. How does it compare to the game-changing perspectives that I proposed two years ago?
The three mantras of my January 2021 post were:
- Contextualization
- Federated semantics
- Accountability
The patterns are intertwined, really:
- You must establish the relevant context(s)/semantics/accountability requirements,
- Then you must discover the dependencies between the relevant components,
- And then you must compare what you have in terms of specialties with what you must deliver in terms of a robust solution to the business.
For contexts, we can mention specialties such as characteristics of dependencies within and between contexts:
- Cardinalities
- Optionalities
- Inheritance
- Associations, etc.
For semantics specialties can be characteristics within and between semantics:
- Forms of representation
- Quality
- Authoritative and legislatory aspects (compliance, etc.)
- Standard semantic within industry domains, etc.
- Metadata changes
Finally, for accountability the issues are, within and between project boarders:
- Authoritative and legislator-y aspects (“does it hold in court” etc.)
- Multi-temporality (and changes to such schemes over time)
- Quality (of registration and of the accountability)
- Retention
- Metadata changes
- Combination of data with different levels of precision, temporality, and even different data types
In (very) general terms, the concerns can be listed as these:
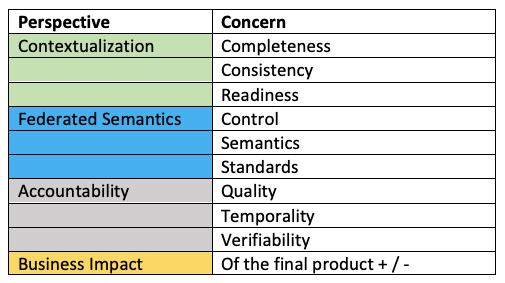
Unfortunately, the concerns are depending on each other in a complex mesh:
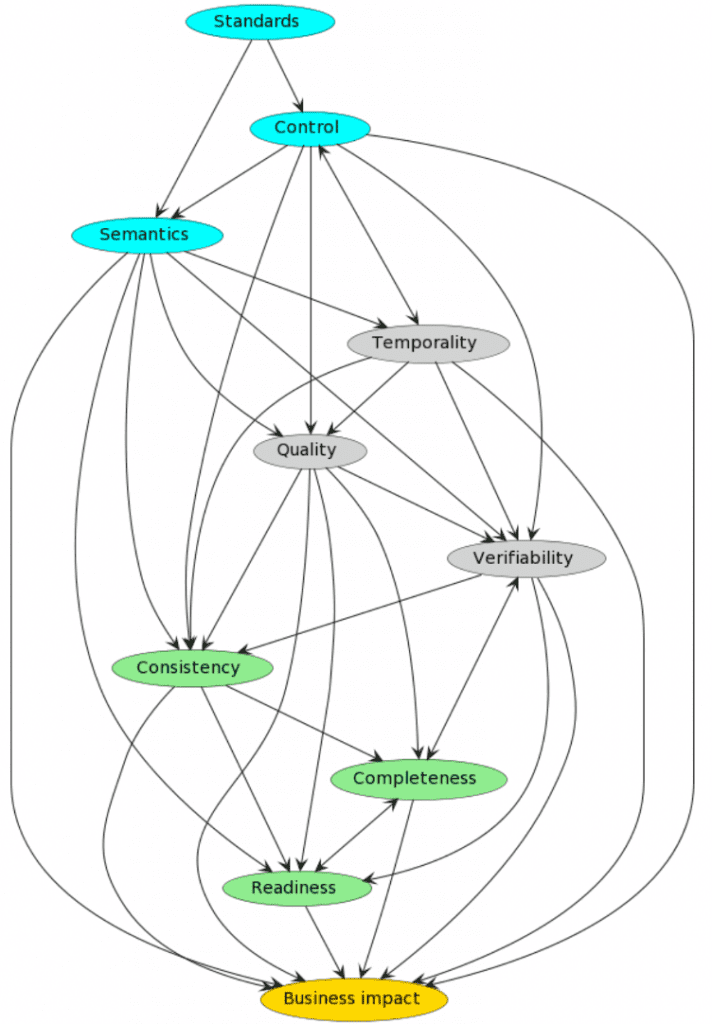
Take some moments to infer the nature of the dependencies (prerequisites and co-variance) between the concerns.
Let us dig down one level in each of the three perspectives.
Federated Semantics
Yes, this sounds like data models, but here in 2023 we do not do UML that much anymore. Easier and semi-intelligent solutions are at hand. So, don’t shy away, yet.

Accountability
Having established what (semantics) you are talking about it is time to investigate the various aspects of reliability of data.
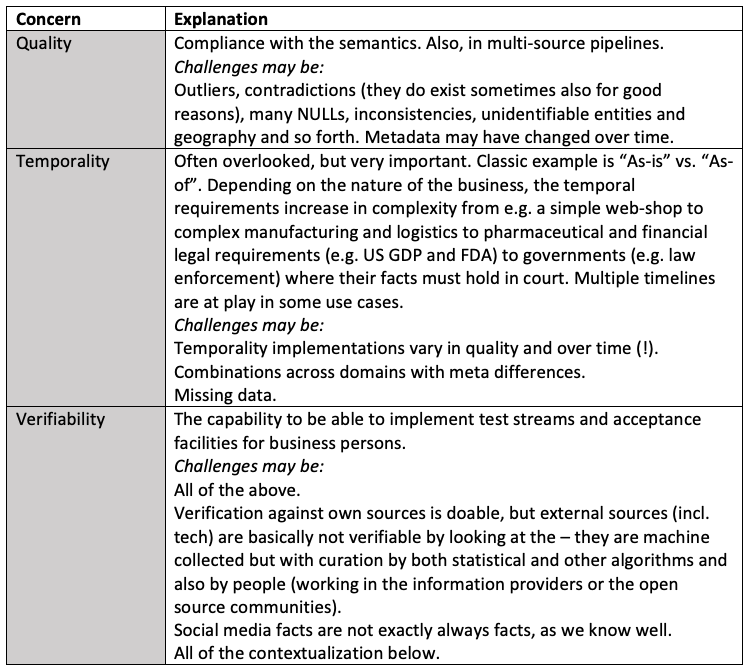
Contextualization
These are final validations to determine the business impact, which can be delivered.

Causes and Costs of Data Debt
I have tried to point you to the issues to watch out for in the little analysis model above. Other people have written very good and deep posts about data debt. For example:
There are plenty of reasons (excuses) for leaving something undone – until hopefully later.
John Ladley, who is a very knowledgeable person with a deep understanding of the impact of data on business results, gives his best advice in the post referenced above. Enjoy his “data debt quadrant” in the post!
But data debt comes at a cost. John Ladley risks his neck at a possible 10% impact on the annual IT costs spent on dealing with data debt items.
That is just the tangible development costs. I maintain that there might also be worse side effects such as customer dissatisfaction, lost revenue, too low profits, etc.
One of my favorite horror stories is about a multinational B2C company that wanted to implement a new sales reporting scheme. They built it collecting data from a number of ERP systems running in different countries – only to discover that the consolidated data base was missing product category hierarchy information in more than 50 % of the sales report lines! That delayed the project with several months, where young, tough, controllers took turns visiting the different daughter companies … If they had known that beforehand, the project would probably have looked different.
Automation to the Rescue?
Basically, there are two types of automated help possible:
- Knowledge based on prepared semantics and/or acquired metadata from APIs from tech or open-source information providers, or
- Statistical (guessing) techniques (ML) supplemented with entity recognition all based on data at hand
The vendor and open-source opportunities develop quickly, so the following are just my bets as of the time of writing. I have tried to rate the attractiveness (0 to 10) of the two approaches across the concerns:

Of course, these ratings can be debated. However, I think the recommendation is clear: Wherever you can, you should look for semantics-based input. The business impact will improve, and the reliability will be higher.
The opportunities are certainly there. The tools vary wildly across different platform categories – data fabric, data catalogs, data mesh, ETL, semantic media, semantic layers, and all the rest. Be careful out there, but do take advantage of semantic technologies!
2023 Opportunities
Fresh out here in 2023 is a new book by Andrew Iliadis of Temple University: “Semantic Media – Mapping Meaning on the Internet.” He comes from the information science side of the house and has a nice, pragmatic, and utility-oriented approach to what we can learn from semantic media.
There are plenty of those today: Google, Wikidata, Amazon, Facebook, IBM, eBay, Apple, Microsoft, and more (mentioned in the order of appearance in the book). Almost all of them are graphs (semantic graphs and a few property graphs). Some of them are in “pre-GA,” some are open source, but most are proprietary. Note that despite the big knowledge graphs used by Google and the others are built from very large datasets, there is some curation (automated and manual) applied, and there are several stories about incorrect search engine results. In fact, search engines are somewhat yesterday. Today it is about providing information – in a one-stop shopping manner.
In this space you find knowledge bases and ditto graphs, knowledge panels and, not least, APIs. All are potential sources of information having structured formats (semantic metadata). And, yes, it is heavily influenced by RDF/OWL and related semantic technologies. This is a rich pond for you to fish in in 2023! Keep me updated when you get a big catch!
Andrew’s book is not a how-to textbook. But I am sure you will find some useful directions. The first three below are inspired by his book, and they are accompanied by an example of an industry sector semantic standard and the last two are examples of how to get semantics into property graphs:
| Semantics | URL | Comment |
| Wikidata | wikidata.org/wiki/Wikidata:Main_Page | Open source, influenced by Google |
| Google Knowledge Graph Search API | cloud.google.com/enterprise-knowledge-graph/docs/search-api | Pre-GA |
| Microsoft Search API | learn.microsoft.com/en-us/graph/search-concept-overview | Microsoft context, but APIs to many other |
| The Financial Industry Business Ontology (FIBO) | github.com/edmcouncil/fibo | EDM Council, open community. A good example of very many open semantic ontologies and taxonomies. |
| Going meta | neo4j.com/video/going-meta-a-series-on-graphs-semantics-and-knowledge/ | 11 episodes about metadata and semantics – Neo4j |
| Neosemantics | neo4j.com/labs/neosemantics/ | Neo4j RDF & Semantics toolkit |
So, what it all boils down to is that it is indeed possible to do something to bring down data debt when developing analytics pipelines, etc. You can bring in some of this new thinking to help you progress faster and also more safely:
- The combination of contextualization, federated semantics, and accountability dictates that you should (and could) build a knowledge graph in 2023
- You can do that by
- Leveraging APIs to semantic media such as Google, Apple, Microsoft, etc., and/orTake advantage of open semantic sources such as
- WikidataIndustry-standard ontologiesInternational and national standard ontologiesOther more or less open sources such as Opencorporates and many more
- Building it in property graph technology, which has an easier learning curve than RDF
- Leveraging APIs to semantic media such as Google, Apple, Microsoft, etc., and/orTake advantage of open semantic sources such as
- You could use your own knowledge graph as an important part of the data contract with the business (make requirements machine-readable, or you can keep simple textfiles in e.g. PlantUML concept syntax)
- You can use your knowledge graph to make completeness tests as well as look for accountability features, missing information, (lack of) temporality information, and so forth
- You can use a graph prototype as a test and verification platform for the businesspeople
Learning graph database is of the essence. This is it – go for it – I am really excited about this palette of 2023 opportunities! Disruption? Yes, and a good one – solving real problems.
Keep me posted!