Click to learn more about author Thomas Frisendal.
The title of this post sounds as if it is a quote from a Star Trek episode. I don’t believe it is, but a lot of the dialogue involving Lt. Commander Data is indeed about understanding. Here is an example from Star Trek: The Next Generation: Starship Mine (#6.18)” (1993):
”Lt. Commander Data: It has been quite a day. Has it not?
Captain Jean-Luc Picard: [slightly surprised about the comment] Yes, it has.
Lt. Commander Data: However, a change of routine is often invigorating, and can be a welcome diversion after a long assignment.
Captain Jean-Luc Picard: Exactly.
Lt. Commander Data: [after a pause] I understand that Arkaria has some very interesting weather patterns.
Captain Jean-Luc Picard: [bewildered] Mr. Data? Are you all right?
Lt. Commander Data: Yes, sir. I am attempting to fill a silent moment with non-relevant conversation.
Captain Jean-Luc Picard: Ah. Small talk.
Lt. Commander Data: Yes, sir. I have found that humans often use small talk during awkward moments. Therefore, I have written a new subroutine for that purpose. How did I do?
Captain Jean-Luc Picard: Perhaps it was a little… too non-relevant.”
Communication is indeed complicated. Making machine-assisted communication somewhat problematic. Remember that Lt. Commander Data was a Soong-type android equipped with a sophisticated positronic brain. That sounds like AI to me… A lot of that going around these days.
We do need to be able to generate (at least big parts of) data models semi-automatically because of several of the V’s of Big Data. This requirement was discussed in my last post (State of the Art of Data Modeling?). Here we will look at the border zones between what can be automated and what definitely requires a human intervention, when it comes to “getting things right” (solve some real business problems in a business fashion).
Data models are vehicles of communication with human beings. The beings being business people as well as system developers. All need to understand the structure and the meaning of a given context (the scope of the data model). By tradition data models are diagrams of various kinds normally of the technical ER-diagram style or maybe the even more technical UML class diagram styles.
What happens if a data model representation communicates in misleading manners? Like as in this scene:

Photo Credit: Wikimedia Commons.
The arranged photograph above is not really wrong but our intuition plays games with us. Did he really loose his head? Or what about this more diagrammatic looking representation of of something abstract in this picture?
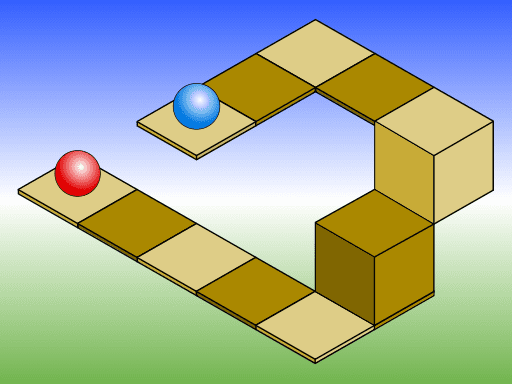
Photo Credit: Wikimedia Commons
What we see above are impossible physical connections suggested to us by our (unconscious) visual perception system. See also this one:

(From an invite to a visual perception seminar arranged by City University of New York in 2013, Creative Commons).
Finding #1: Visual Appearance is important
We now know that our perceptive systems are trying to help us by way of making heuristics-based short-cuts designed to help us react with speed in complex contexts. In fact, recent research at University of London (E. Travers et al, https://osf.io/preprints/psyarxiv/7becr) establishes that consciousness probably evolved as the way our brain switches to “special handling necessary – context is unreliable” mode. The paper is titled “Learning Rapidly about the Relevance of Visual Cues Requires Conscious Awareness”.
The perceptive aspects we can deal with by way of choosing visual appearances, which are simple (not misleading or counter-intuitive), and which also present relatedness in all its aspects (kinds of relationships and their names) using the pointer-metaphor.
Such a diagramming style is found in the property graph model, see for example my own work on graph data modeling (graphdatamodeling.com ).
Let us try to be more precise. When we communicate (a data model) we want:
- High precision, and
- Correct (and to the point) expressiveness.
Finding #2: Data Model Precision is defined by Context Quality
If data models are to be derived from the data, we need to master the Data Quality aspects rather completely. As it happens, a given data set may be interpreted in more than one way, and there are bound to be situations, where human judgement is necessary. We are still better than machines when it comes to understanding a given context. Why is that? Because humans set the rules of the context. In our very human ways we leave room for oversights, simplifications, peculiar terminology and laissez-faire “known errors”. The rightful owners of the business terminology are the business people, and they are more human than they are androids.
The path from data values to a context description (another way to describe what a data model is) is long and works upwards in multiple layers. The bottom layers being traditional stuff from Data Quality but the upper layers really do not have a good name, yet. “Smart Data Discovery” is more a marketing term and there are no clearly sovereign technologies. I suggest we call the upper things “Context Quality Management”. (I agree with Barry Devlin that “metadata” should be replaced with a fresh approach).
Finding #3: Top-Down meets Bottom-Up in a collaborative Data Catalog
Getting at (more) “precise” data models imply working with a full understanding of the context in scope. The data can talk to us, but only within the limits of its quality – both content and naming matter, seriously much so.
There is a place for working top-down, as in this satellite image of the Castle of Elsinore (“Hamlet’s Castle”):
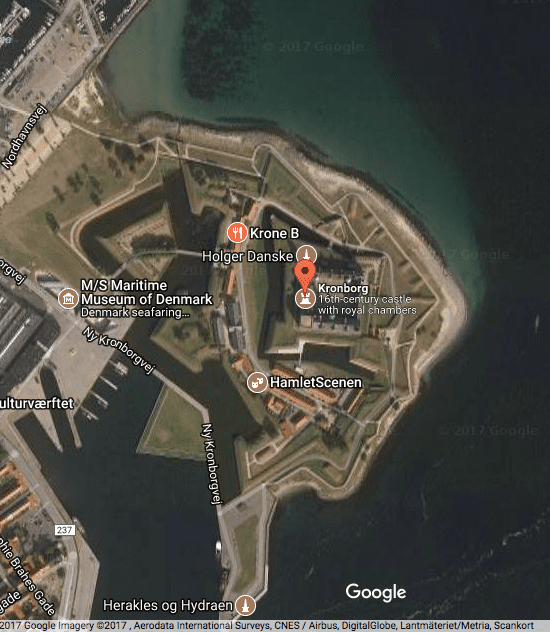
Photo Credit: Google Maps
Top-down can be understood as working from the business context and breaking it down into detailed concepts and relationships; using techniques such as brainstorming sessions and the like.
There is also a place for bottom-up field work as in this picture from Antarctica:

Photo Credit: Wikimedia Commons
Bottom-up is the looking at data first, schema last approach to Data Modeling. Exploration is the name of the game; like in “what is around that point”? This is where the AI-assistance to data modeling comes to play.
But wait, there is one more approach, which is looking very promising. Alation, and other companies, are working with “crowd-sourcing” “data catalogs”. Done right, I think this can be very helpful.
A good bet today is that the collaborative data catalog (like that offered by Alation for instance) can be the glue that kits together top-down, bottom-up, and common business knowledge (context). The collaboration, if you can get it to work, can greatly improve the context quality. You need to stimulate the actual cooperation between the top-down thinking and the bottom-up thinking. And you need business knowledge at hand for quality assurance of the collaborative decisions.
These are very interesting developments. I am seriously interested in hearing about some real experiences with such approaches. If you would like to share, please send me an email at: info@graphdatamodeling.com.